http://data.seoul.go.kr/openinf/fileview.jsp?infId=OA-12061
위와 같은 경로에서 서울시의 고등학교 데이터를 얻어서 데이터 시각화를 시도해보았습니다.


위와 같은 데이터 형태를 가지고 있습니다.
주소, 학년별 인원수, 지역, 남녀인원, 공학여부 등등 다양한 정보가 많이 들어있습니다.
1 2 3 4 5 | import numpy as np import pandas as pd from pandas import Series, DataFrame data = pd.read_excel('data/seoulHighSchool.xlsx') | cs |
위와 같이 데이터를 판다스로 읽어옵니다.
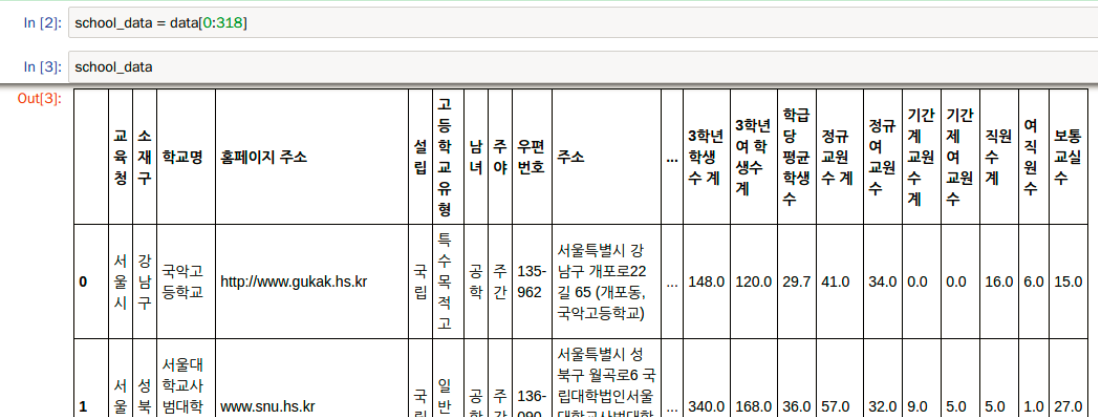
위와 같이 정보를 불러왔습니다.
data[0:318] 로 가져온 이유는 아래 쓸모 없는 데이터가 같이 들어와서 잘라서 필요한 부분만 취하기 위해서 했습니다.
1 2 3 4 5 6 7 8 9 10 | %matplotlib inline def getEachNum(column_name): result = {} for each in range(school_data[column_name].size): if result.get(school_data[column_name][each], 0) == 0: result[school_data[column_name][each]] = 1 else : sub_value = result[school_data[column_name][each]] result[school_data[column_name][each]] = sub_value + 1 return result | cs |
위와 같이 함수를 짰습니다.
getEachNum에 column 이름을 넣으면 그 column 에 있는 정보를 key 에 넣고 갯수를 value 에 넣어서 dictionary 를 만듭니다.
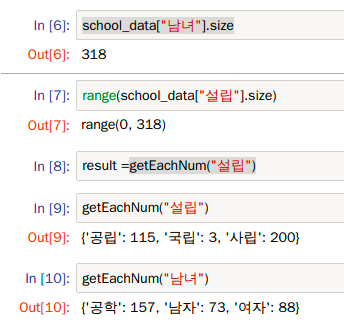
결과는 위와 같습니다.
getEachNum() 에 원하는 column 값을 넣으면 각각의 아웃풋이 나오게 됩니다.
1 2 3 4 5 6 7 8 9 10 11 12 | def showEachNum(result): graphNames = [] values = [] for key in result.keys(): graphNames.append(key) values.append(result[key]) x_range = numpy.arange(len(result)) plot.bar(x_range, values, align = 'center') plot.xticks(x_range, graphNames) plot.show() | cs |
다음으로는 위에서 얻은 데이터를 가지고 graph 를 그리는 메소드를 제작하였습니다.
5줄에서 graphName 들을 list로 만들어주고 값들은 6줄에서 각각 넣어줍니다.
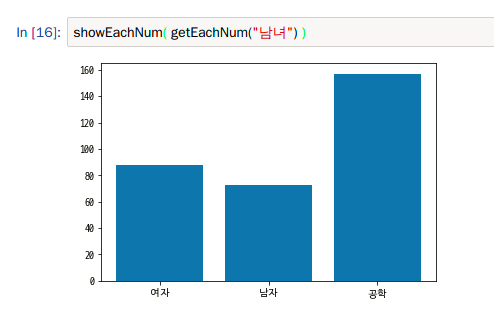
결과는 위와 같습니다.
서울에는 남여 공학 고등학교가 굉장히 많군요.
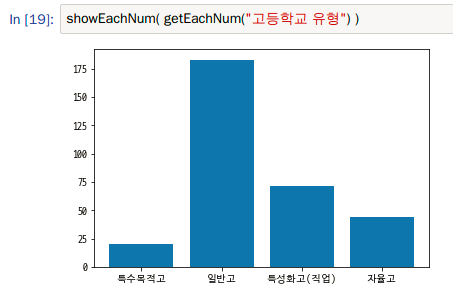
고등학교 유형은 위와 같이 일반고가 주로 많고 특성화고가 꽤 많은 것 같습니다.
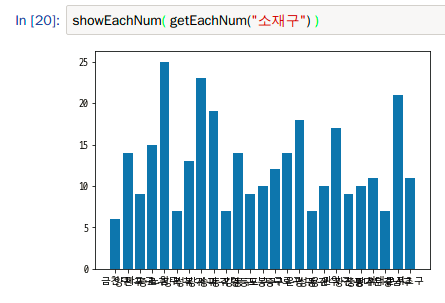
소재구를 그래프로 표시하니 상당히 보기가 어렵더라구요.
그래서 그래프의 x 축을 y 축과 바꾸고 그래프 크기를 키우는 함수를 만들었습니다.
1 2 3 4 5 6 7 8 9 10 11 12 | def showEachNum_X(result): graphNames = [] values = [] for key in result.keys(): graphNames.append(key) values.append(result[key]) y_range = numpy.arange(len(result)) plot.figure(figsize=(10,8)) plot.barh( y_range, values, align = 'center') plot.yticks( y_range, graphNames) plot.show() | cs |
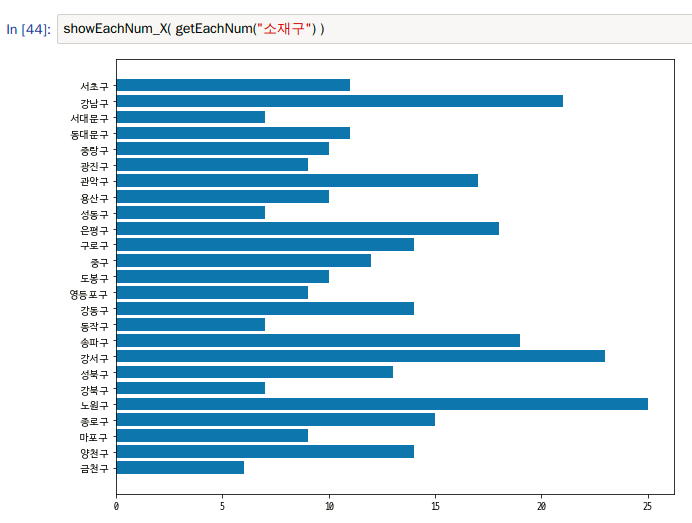
결과는 위와 같습니다.
노원구에 가장 고등학교 수가 많고 금천구에 가장 고등학교 수가 적은 것을 확인 할 수 있습니다.
다음으로는 학생 수와 교원 수의 상관관계를 알아보겠습니다.
1 2 3 4 5 | stuTeaRelation = [ [ school_data['1학년 학생수 계'][each] + school_data['2학년 학생수 계'][each] + school_data['3학년 학생수 계'][each] , school_data['정규 교원수 계'][each] ] for each in range(school_data['1학년 학생수 계'].size) ] | cs |
위와 같이 list comprehension 을 통해서 학생과 선생님의 수를 [ 1~3학년 까지의 학생수, 선생님의 수 ] 를 하나의 행으로 하는
318*2 크기의 matrix 를 제작합니다.

결과 값은 위와 같습니다 .
1 2 3 4 5 6 7 | import numpy as np import matplotlib.pyplot as plt relationData = np.array(stuTeaRelation) plt.figure(figsize=(10,8)) plt.scatter(relationData[:, 0] , relationData[:, 1], color= 'c', marker='^') plt.show() | cs |
이를 위처럼 그래프로 보여주면 ??
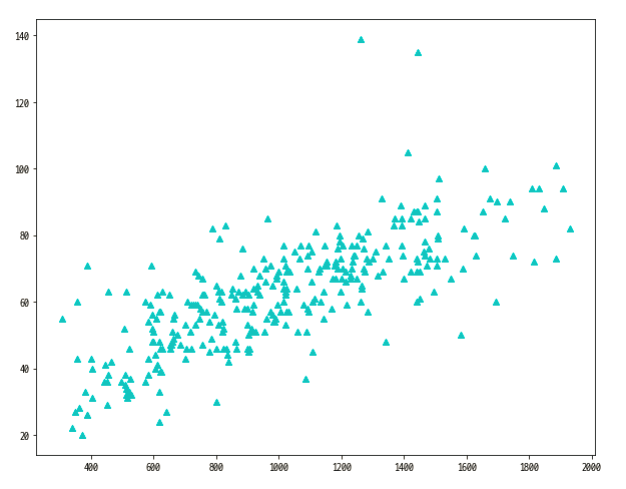
위와 같은 결과가 나옵니다.
몇 개의 값을 제외하고는 꽤 규칙적인 것 같습니다.
위의 그래프에서 선형 회귀 함수를 그려보겠습니다.

위와 같이 sudo pip3 install statsmodels 라는 명령어를 통해서 statsmodels 를 설치해줍니다.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 | import statsmodels.api as sm import numpy as np import matplotlib.pyplot as plt relationData = np.array(stuTeaRelation) plt.figure(figsize=(10,8)) plt.scatter(relationData[:, 0] , relationData[:, 1], color= 'c', marker='^') X = relationData[:, 0] Y = relationData[:, 1] results = sm.OLS(Y,sm.add_constant(X)).fit() X_plot = np.linspace(min(X),max(X),100) plt.plot(X_plot, X_plot*results.params[1] + results.params[0]) plt.show() | cs |
위와 같이 X 와 Y 를 정한 후에 statsmodels 의 OLS 메소드를 사용하여 results 를 구합니다.
그리고 그래프를 그려주면
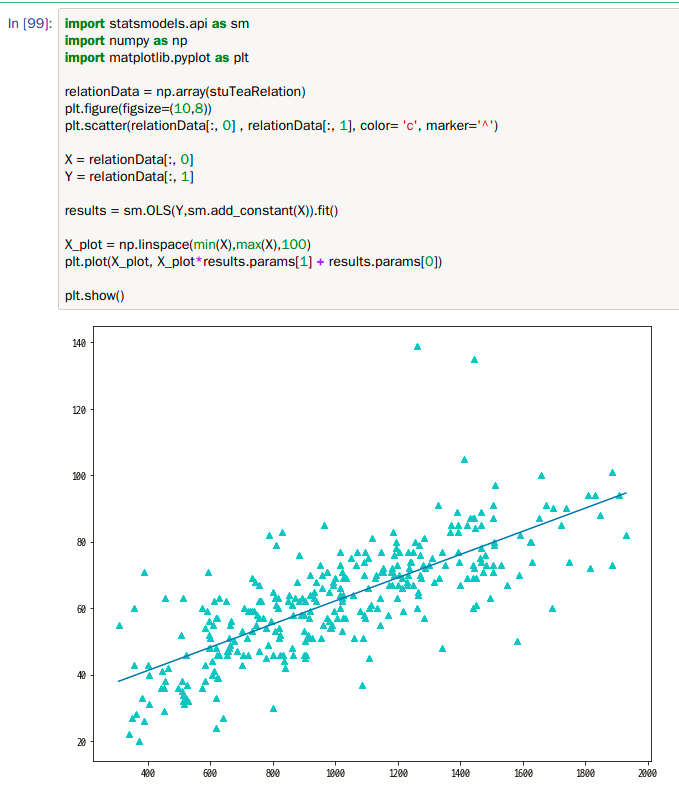
위와 같은 결과가 나옵니다.
수학적으로 의미있는 분석은 제대로 못해보았지만 다음에는 공부를 좀 더 해서 다른 데이터를 제대로 분석 해 보아야겠습니다.