정규 분포에 대한 내용은 많이 사용되지만, 제대로 개념 확립이 되던 부분이 아니라서 제대로 정리 해 보았습니다.
고등학교 때 배우지만, 시험 보기에 급급하여 제대로 배우지 않고, 수식만 외워서 수능때도 적용했던 기억이 납니다.
정규분포
확률론과 통계학에서, 정규분포(正規分布, 영어: normal distribution) 또는 가우스 분포(Gauß分布, 영어: Gaussian distribution)는 연속 확률 분포의 하나이다. 정규분포는 수집된 자료의 분포를 근사하는 데에 자주 사용되며, 이것은 중심극한정리에 의하여 독립적인 확률변수들의 평균은 정규분포에 가까워지는 성질이 있기 때문이다.
정규분포는 2개의 매개 변수 평균 



사실 설명만 보면 이해는 잘 되지 않습니다 .
위의 설명을 이해하기 위해서는 중심 극한 정리라는 개념이 필요합니다.
중심극한정리
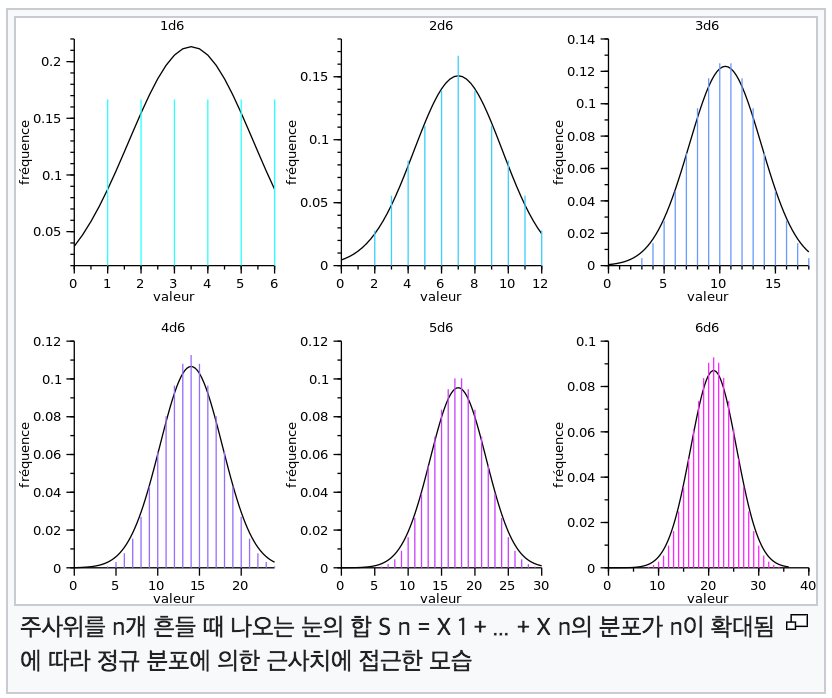
확률론과 통계학에서, 중심극한정리(中心極限定理, 영어: central limit theorem, 약자 CLT)는 동일한 확률분포를 가진 독립 확률 변수 n개의 평균의 분포는 n이 적당히 크다면 정규분포에 가까워진다는 정리이다. 수학자 피에르시몽 라플라스는 1774년에서 1786년 사이의 일련의 논문에서 이러한 정리의 발견과 증명을 시도하였다. 확률과 통계학에서 큰 의미가 있으며 실용적인 면에서도 품질관리, 식스 시그마에서 많이 이용된다.
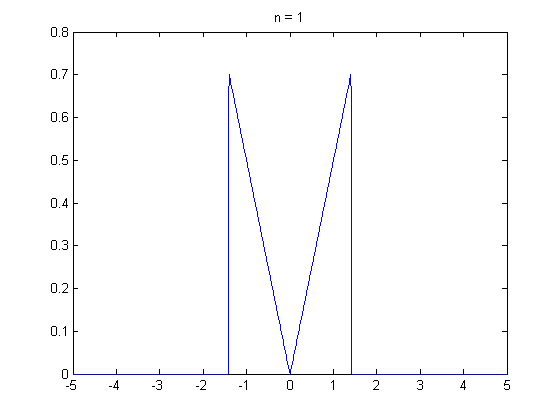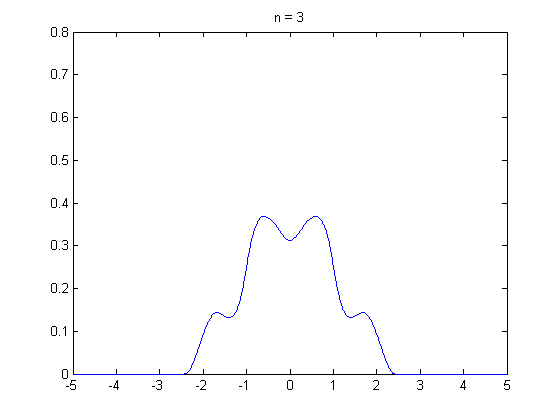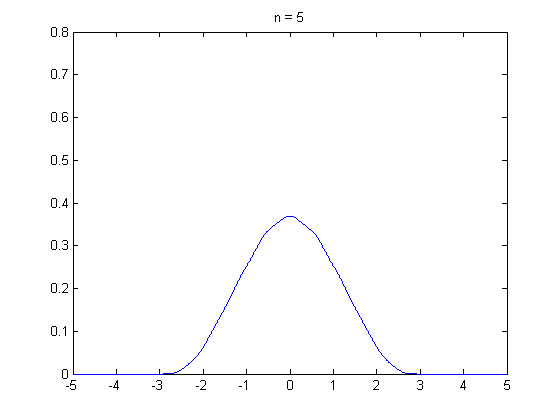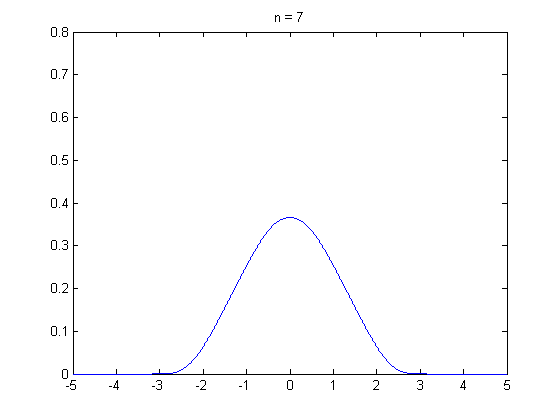
즉, 쉽게 말하면 "동일한 확률을 가진 변수들이 적당히 크면, 해당 변수들의 평균은 일정한 패턴을 가진다. 이는 정규 분포다" 라고 생각하면 될 것 같습니다.
즉, 평균의 모양이 일정하다 ! 가 핵심입니다.
R 언어를 사용해서 테스트 해보겠습니다.
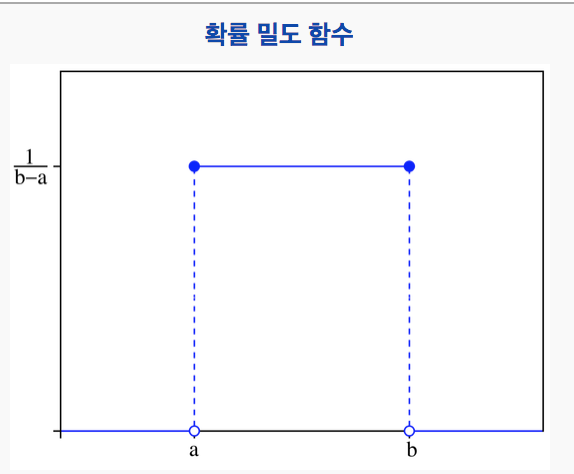
사용하는 균등 분포는 아래와 같이 모든 확률이 동일합니다.
a, b 는 각각 0 과 1입니다.
>> 소스코드
# (표준)정규분포에서 난수 생성 dat_norm1 <- rnorm(100) # 0~1 사이의 균등한 확률로 뽑히는 숫자 중 100 개를 뽑는다. qplot(dat_norm1, binwidth=0.05) # 그래프로 표현 dat_norm2 <- rnorm(1000) # 0~1 사이의 균등한 확률로 뽑히는 숫자 중 1000 개를 뽑는다. qplot(dat_norm2, binwidth=0.05) # 그래프로 표현 dat_norm3 <- rnorm(100000) # 0~1 사이의 균등한 확률로 뽑히는 숫자 중 10000 개를 뽑는다. qplot(dat_norm3, binwidth=0.05) # 그래프로 표현
# 0~1 사이의 균등한 확률로 뽑히는 숫자 중 100 개를 뽑는다.
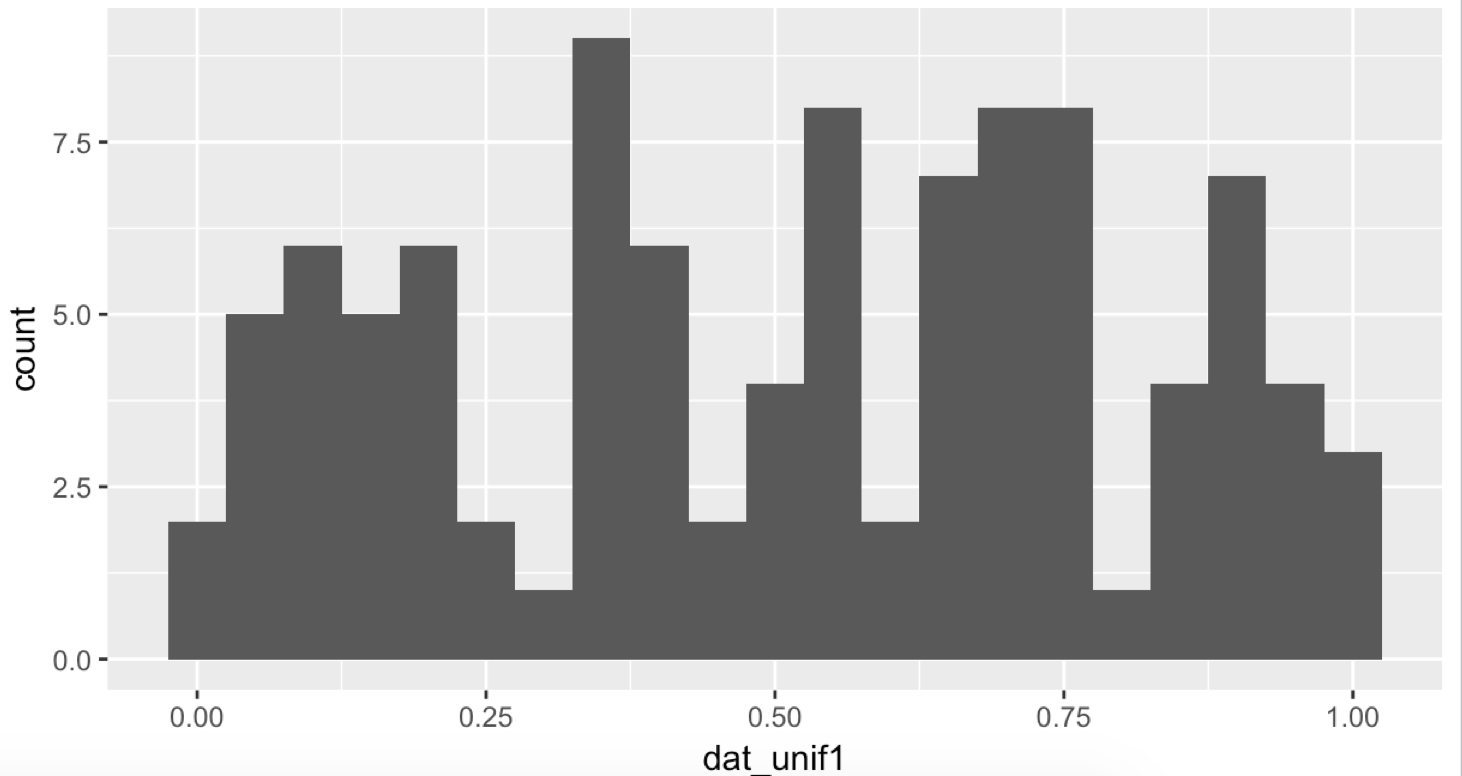
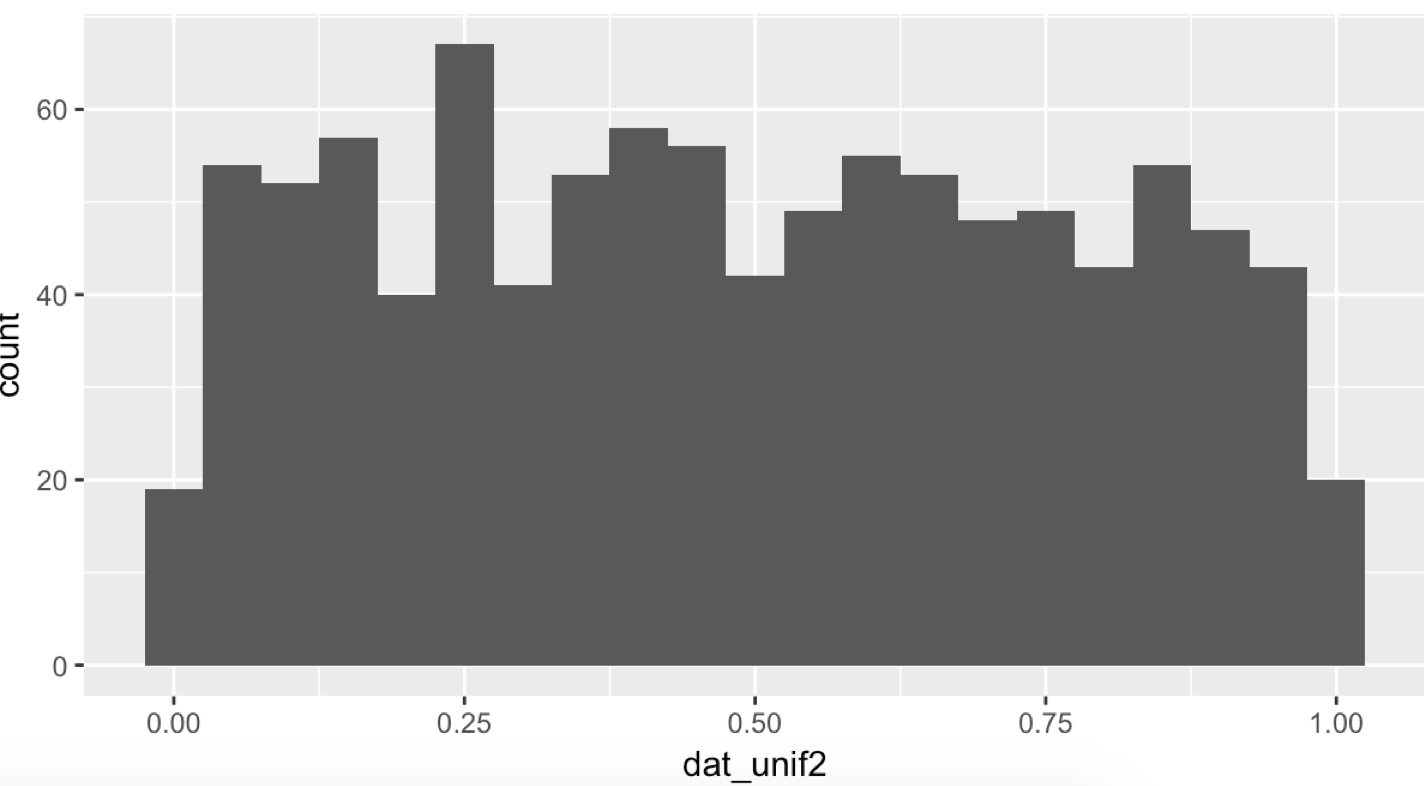
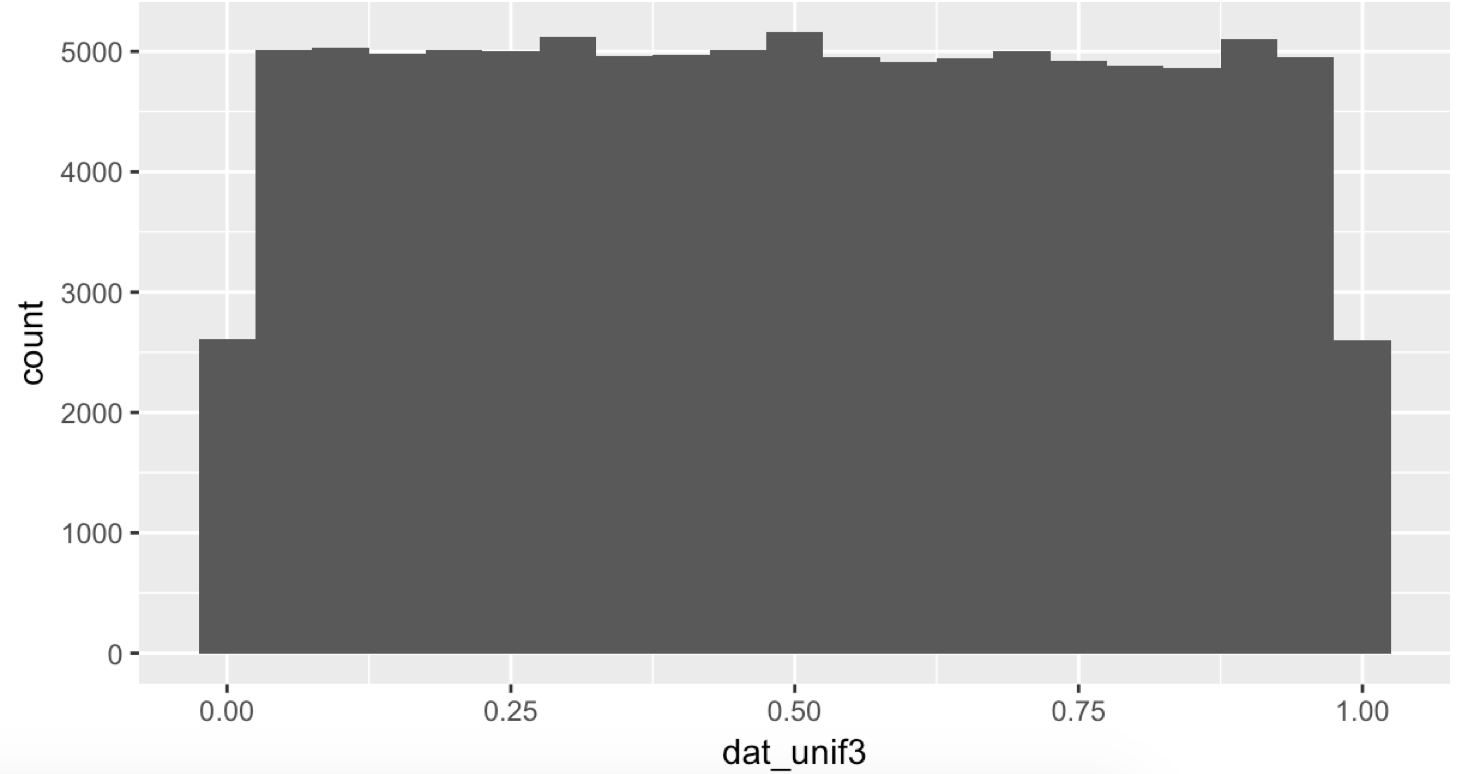
숫자가 늘어나면 늘어 날 수록 원래의 그래프와 가까워 지는 것을 확인 할 수 있습니다.
끝이 반토막인 이유는 0~0.025 , 1~1.025 같은 경우 다른 구간의 간격은 0.05 이므로 반토막이기 때문에,
그 사이에 나올 숫자가 절반 정도 되기 때문입니다.
nsim <- 10000 xbar <- numeric(nsim) for (i in 1:length(xbar)){ x <- runif(1); # 균등 분포에서 하나를 뽑는다. xbar[i] <- mean(x) # 평균을 계산한다. } qplot(xbar) # 그래프를 그린다. nsim <- 10000 xbar <- numeric(nsim) for (i in 1:length(xbar)){ x <- runif(2); # 균등 분포에서 2개를 뽑는다. xbar[i] <- mean(x) # 평균을 계산한다. } qplot(xbar) # 그래프를 그린다. nsim <- 10000 xbar <- numeric(nsim) for (i in 1:length(xbar)){ x <- runif(10); # 균등 분포에서 10 개를 뽑는다. xbar[i] <- mean(x) # 평균 계산을 한다. } qplot(xbar) # 그래프를 그린다. nsim <- 10000 xbar <- numeric(nsim) for (i in 1:length(xbar)){ x <- runif(20); # 균등 분포에서 20 개를 뽑는다. xbar[i] <- mean(x) # 평균 계산을 한다. } qplot(xbar) # 그래프를 그린다. nsim <- 10000 xbar <- numeric(nsim) for (i in 1:length(xbar)){ x <- runif(100); # 균등 분포에서 100개를 뽑는다. xbar[i] <- mean(x) # 평균을 낸다. } qplot(xbar) # 그래프를 그린다.
# 균등 분포에서 하나를 뽑는다. 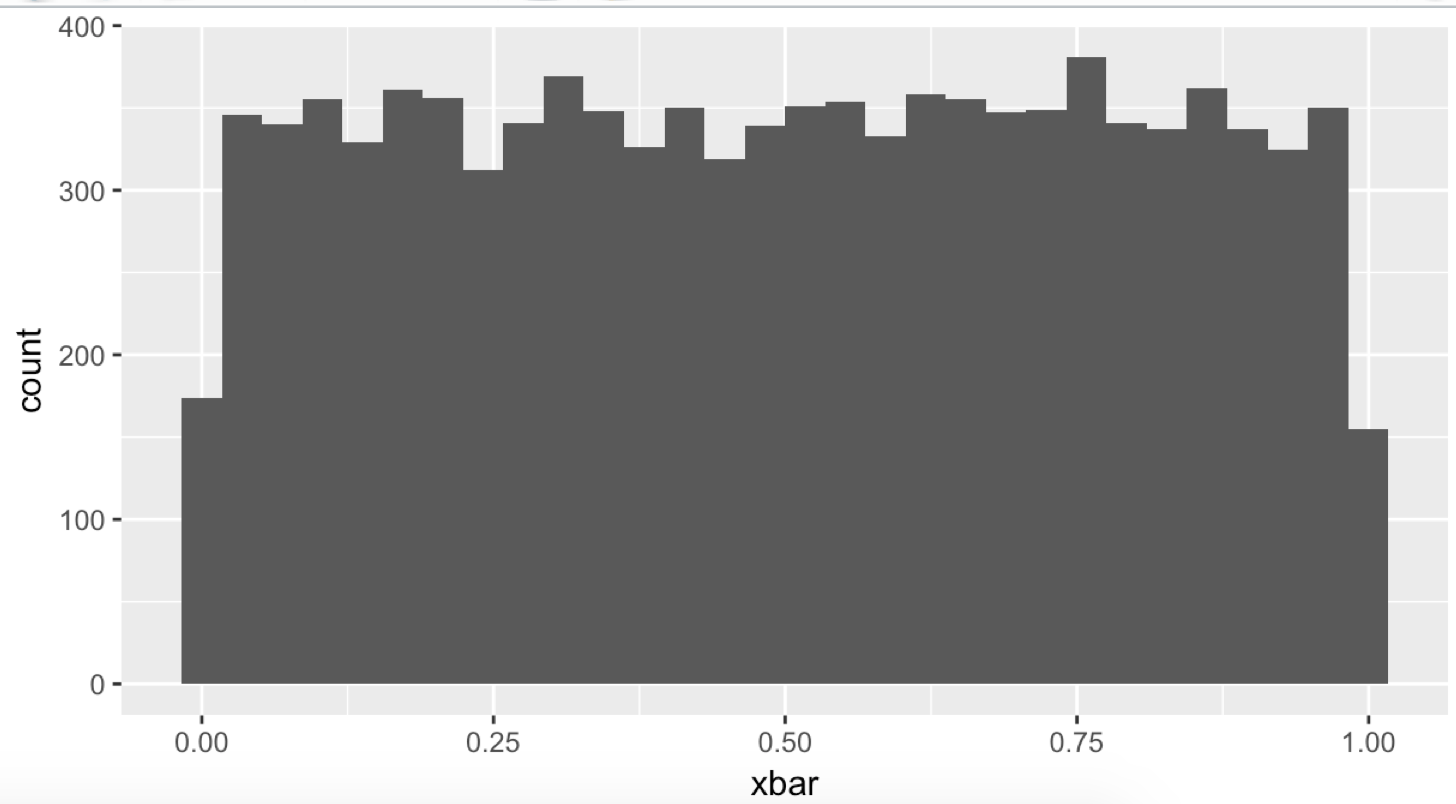
# 균등 분포에서 2개를 뽑는다.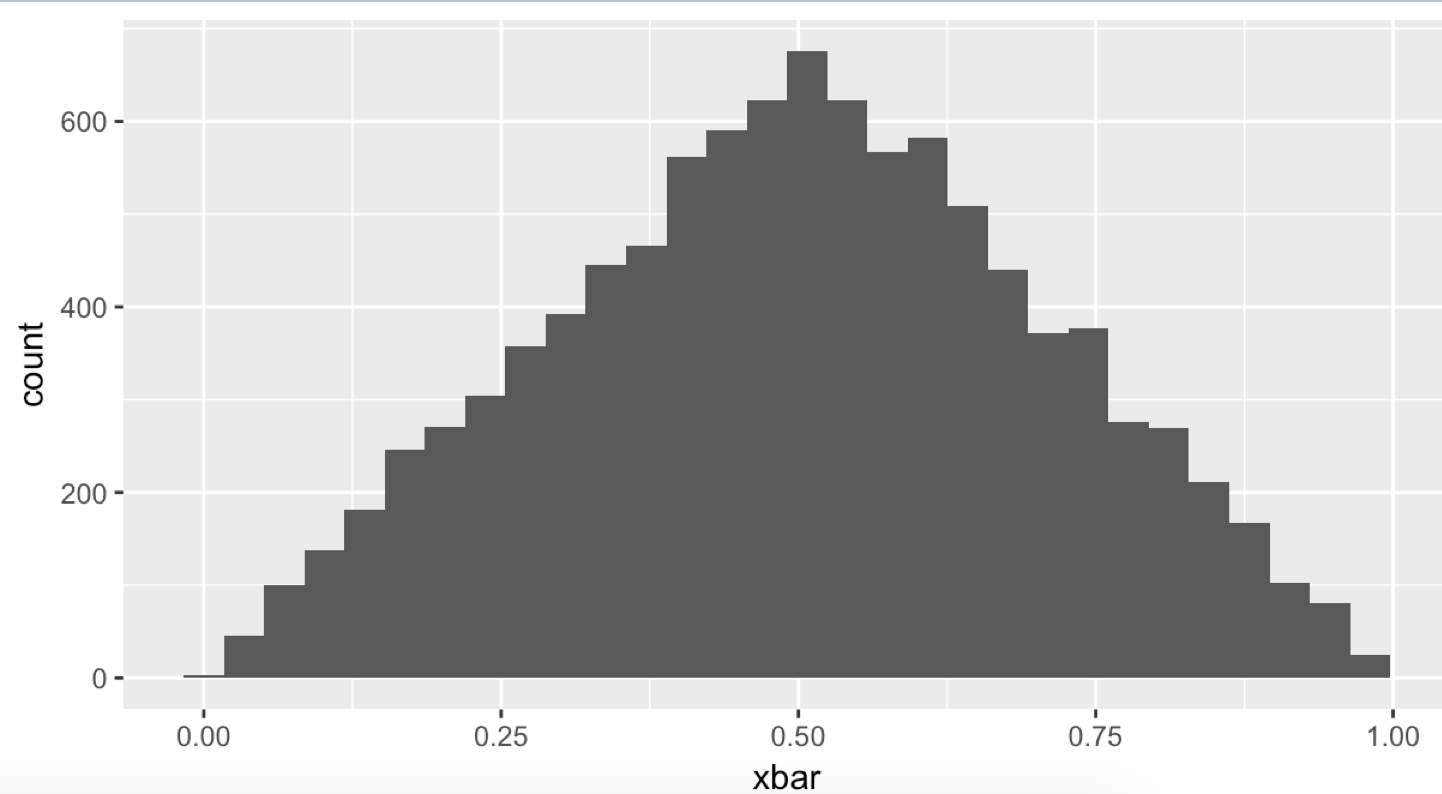
# 균등 분포에서 10 개를 뽑는다. 
# 균등 분포에서 20 개를 뽑는다.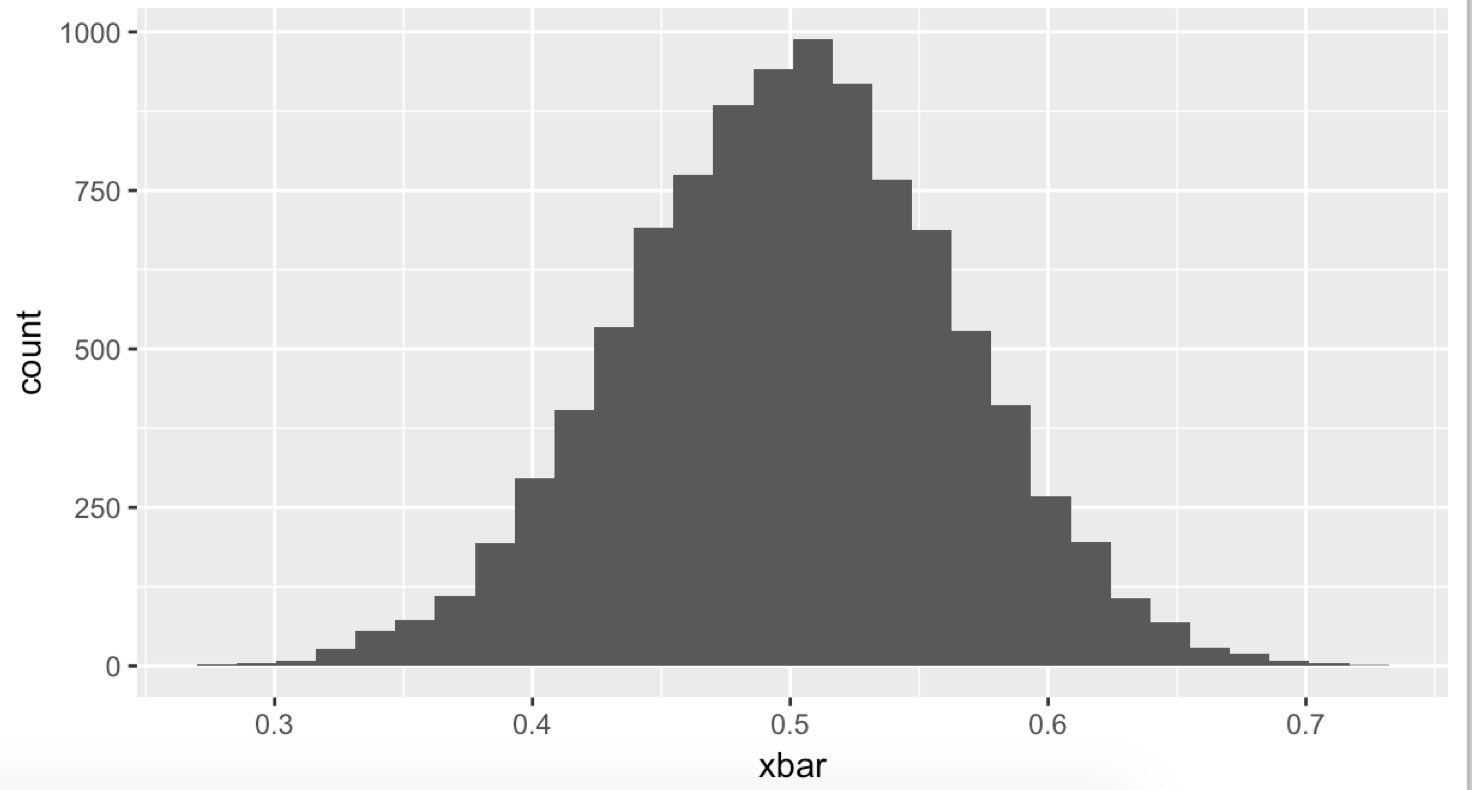
# 균등 분포에서 100 개를 뽑는다.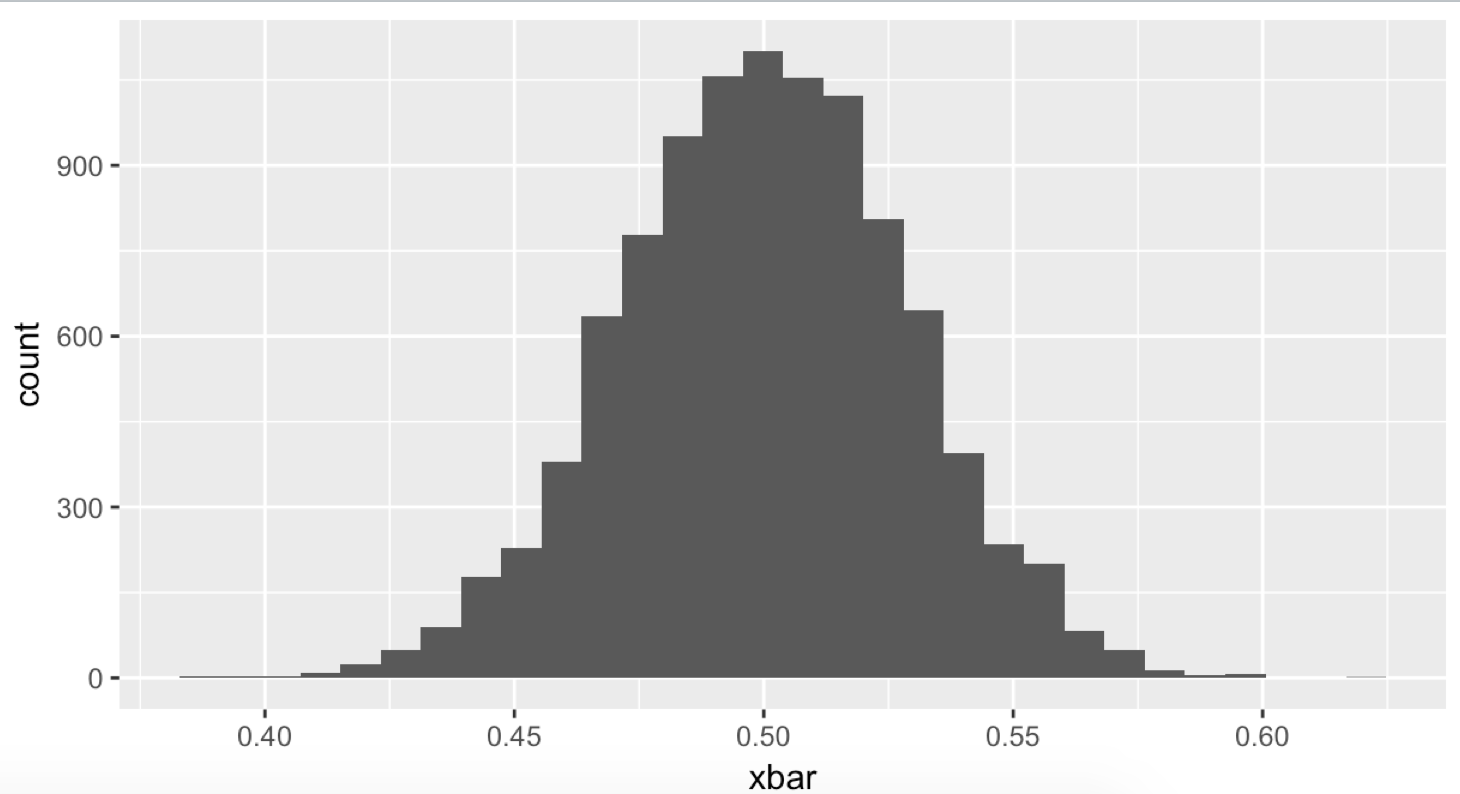
하나일 때는 균등 분포를 뽑는 것과 동일하지만 ( 평균이 아니라 하나의 값이므로 )
수가 많아질수록 점점 종모양에 가까워지는 모습을 볼 수 있습니다.
- 출처 -
위키백과