인공지능 Deep voice를 이용한 TTS(음성합성) 구현하기 _ 손석희 앵커
위 ppt는 deview 2017 에서 TTS 에 관련하여 Taehoon Kim 님이 발표한 자료입니다.
위 동영상에서 자세하게 설명해주고 있습니다.
해당 자료를 바탕으로 TTS를 구현해보겠습니다.
제가 일부 수정한 소스코드는 아래의 링크를 참조하시면 됩니다.
https://github.com/melonicedlatte/multi-speaker-tacotron-tensorflow
1. 필수 요소 설치
- 아래의 명령어를 통하여, git pull을 받습니다.
git init git pull https://github.com/carpedm20/multi-Speaker-tacotron-tensorflow
- pip를 통해서 필요한 요소들을 설치합니다.
버전이 약간 상이한 부분이 있는데, 해당 부분은 수정 해줍니다.
requirements.txt 의 요소들의 버전을 수정하여 해결합니다.
pip3 install -r requirements.txt
python3 -c "import nltk; nltk.download('punkt')"2. 필요한 한국어 데이터 셋 설정하기
2-0. 데이터 셋 다운로드
sudo python3 -m datasets.son.download
위의 명령어를 실행하여 datasets/son/download.py 파일을 실행시킵니다.
아래와 같이 설치가 잘 진행됩니다.
➜ sudo python3 -m datasets.son.download
Download news video+text: 4%|███▍ | 28/710 [01:53<46:15, 4.07s/it]
2-1. google speech recognition api 설정
설치가 되는 동안에는 Google Speech Recognition API 를 통해서 받은 credentials.json 이 필요합니다.
https://cloud.google.com/speech-to-text/
위의 링크에서 설명하는 기능입니다.
https://jungwoon.github.io/google%20cloud/2017/10/26/install-gcloud/
먼저 위의 링크대로 gcloud 를 설치해줍니다.
https://jungwoon.github.io/google%20cloud/2018/01/17/Speech-Api/
그 다음으로는 해당 링크를 따라서 설치를 진행합니다.
해당 과정을 수행하면서 son의 데이터 셋 설치가 완료 되었습니다.
Download news video+text: 100%|███████████████████████████████████████████████████████████████████████████████████████| 710/710 [34:42<00:00, 2.93s/it]
2-2. audio 파일을 '말이 없는 구간(침묵)'에서 자르기
sudo python3 -m audio.silence --audio_pattern "./datasets/son/audio/*.wav" --method=pydub위 명령어를 입력하여 침묵 구간을 기준으로 audio 파일을 자릅니다.
audio 파일은 위와 같습니다.
하나의 문장을 기준으로 잘리는 것을 확인할 수 있습니다.
아래와 같이 잘린 파일은 .00xx 와 같은 형태를 가지고 있습니다.
2-3. Google Speech Recognition API 를 사용하여, 오디오에 대한 문장을 출력해줍니다.
sudo python3 -m recognition.google --audio_pattern "./datasets/son/audio/*.*.wav"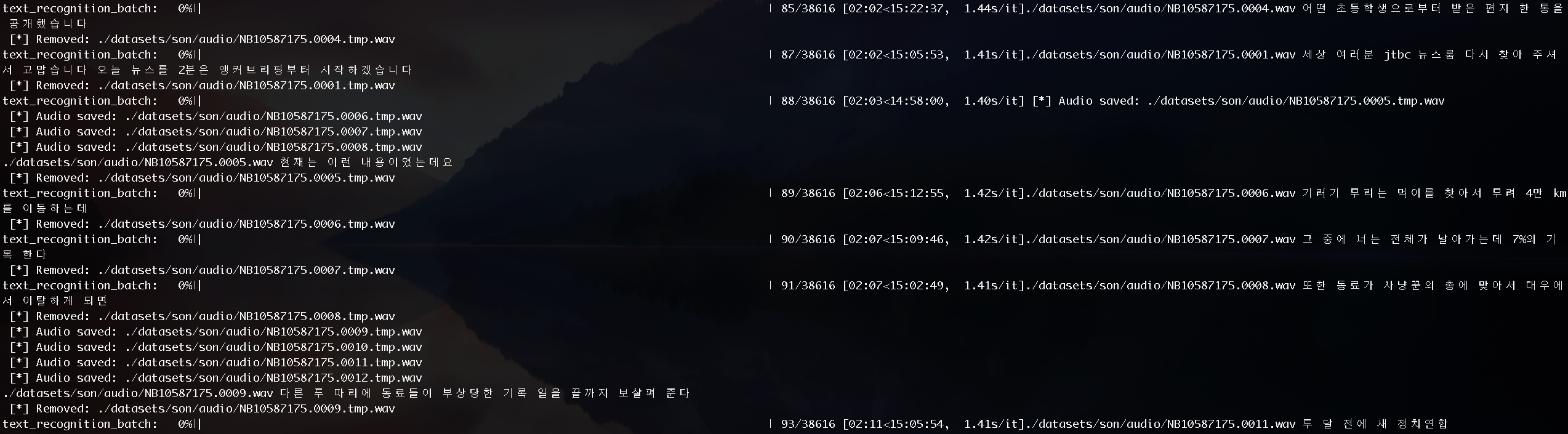
콘솔을 살펴보면 해당 텍스트가 어떠한 값을 가지고 있는지 확인할 수 있습니다.

학습 시간이 매우 오래걸립니다....
2-4. 인식된 텍스트와 진짜 텍스트를 비교하기 위하여, 음성 파일과 텍스트 파일을 쌍으로 연결한 내용을 alignment.json 에 저장합니다.
python3 -m recognition.alignment --recognition_path "./datasets/son/recognition.json" --score_threshold=0.5
UnicodeDecodeError: 'cp949' codec can't decode bytes in position : illegal multibyte sequence
align_text_batch: 0%| | 0/37978 [00:00<?, ?it/s] [!] Converting to english mode
[!] Converting to english mode
[!] Converting to english mode
[!] Converting to english mode
align_text_batch: 100%| ████████████████████████████████████████| 37978/37978 [00:48<00:00, 784.55it/s]
[*] # found: 0.99868% (37928/37978)
[*] # exact match: 0.40993% (15548/37928)
100%|█████████████████████████████████████████████████████████████| 37928/37928 [00:46<00:00, 818.83it/s]
[*] Total Duration : 1 day, 1:56:11 (file #: 37928)
2.5 학습에 사용될 numpy 파일을 생성해줍니다.
python3 -m datasets.generate_data ./datasets/son/alignment.json========================================
[!] Sampling rate: 22050
========================================
[!] Skip recognition level: 0 (use all)
[!] Converting to english mode
17%|██████████ | 6391/37928 [12:34<1:02:05, 8.47it/s]
100%|█████████████████████████████████████████████████████████████████| 37928/37928 [37:55<00:00, 16.67it/s]
[*] Loaded metadata for 37928 examples (26.06 hours)
[*] Max length: 4237
[*] Min length: 19
[*] After filtered: 21066 examples (20.24 hours)
[*] Max length: 991
[*] Min length: 150
3. 모델 학습시키기
single-speaker 모델을 학습 시키기 위한 코드
python3 train.py --data_path=datasets/son
python3 train.py --data_path=datasets/son --initialize_path=PATH_TO_CHECKPOINT$ export CUDA_VISIBLE_DEVICES=0
$ python3 train.py --data_path=datasets/son
[*] MODEL dir: logs/son_2018-07-05_13-48-56
[*] PARAM path: logs/son_2018-07-05_13-48-56/params.json
['datasets/son']
========================================
[!] Detect non-krbook dataset. May need to set sampling rate from 22050 to 20000
========================================
[*] git recv-parse HEAD:
becbd0ab80dbefe64a8fdea4a19856924dd31504
==================================================
==================================================
[*] Checkpoint path: logs/son_2018-07-05_13-48-56/model.ckpt
[*] Loading training data from: ['datasets/son/data']
[*] Using model: logs/son_2018-07-05_13-48-56
Hyperparameters:
adam_beta1: 0.9
adam_beta2: 0.999
attention_size: 128
attention_state_size: 256
attention_type: bah_mon
batch_size: 32
cleaners: english_cleaners
dec_layer_num: 2
dec_prenet_sizes: [256, 128]
dec_rnn_size: 256
decay_learning_rate_mode: 0
dropout_prob: 0.5
embedding_size: 256
enc_bank_channel_size: 128
enc_bank_size: 16
enc_highway_depth: 4
enc_maxpool_width: 2
enc_prenet_sizes: [256, 128]
enc_proj_sizes: [128, 128]
enc_proj_width: 3
enc_rnn_size: 128
frame_length_ms: 50
frame_shift_ms: 12.5
griffin_lim_iters: 60
ignore_recognition_level: 0
initial_data_greedy: True
initial_learning_rate: 0.001
initial_phase_step: 8000
main_data: ['']
main_data_greedy_factor: 0
max_iters: 200
min_iters: 30
min_level_db: -100
min_tokens: 50
model_type: single
num_freq: 1025
num_mels: 80
post_bank_channel_size: 128
post_bank_size: 8
post_highway_depth: 4
post_maxpool_width: 2
post_proj_sizes: [256, 80]
post_proj_width: 3
post_rnn_size: 128
power: 1.5
preemphasis: 0.97
prioritize_loss: False
recognition_loss_coeff: 0.2
reduction_factor: 5
ref_level_db: 20
sample_rate: 22050
skip_inadequate: False
speaker_embedding_size: 16
use_fixed_test_inputs: False
filter_by_min_max_frame_batch: 100%| ██████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 37928/37928 [00:38<00:00, 972.77it/s]
[datasets/son/data] Loaded metadata for 14366 examples (15.81 hours)
[datasets/son/data] Max length: 991
[datasets/son/data] Min length: 150
========================================
{'datasets/son/data': 1.0}
========================================
filter_by_min_max_frame_batch: 100%| ████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 37928/37928 [00:38<00:00, 979.69it/s]
[datasets/son/data] Loaded metadata for 14366 examples (15.81 hours)
[datasets/son/data] Max length: 991
[datasets/son/data] Min length: 150
========================================
{'datasets/son/data': 1.0}
========================================
========================================
model_type: single
========================================
Initialized Tacotron model. Dimensions:
embedding: 256
speaker embedding: None
prenet out: 128
encoder out: 256
attention out: 256
concat attn & out: 512
decoder cell out: 256
decoder out (5 frames): 400
decoder out (1 frame): 80
postnet out: 256
linear out: 1025
========================================
model_type: single
========================================
Initialized Tacotron model. Dimensions:
embedding: 256
speaker embedding: None
prenet out: 128
encoder out: 256
attention out: 256
concat attn & out: 512
decoder cell out: 256
decoder out (5 frames): 400
decoder out (1 frame): 80
postnet out: 256
linear out: 1025
2018-07-05 13:50:22.378455: W tensorflow/core/platform/cpu_feature_guard.cc:45] The TensorFlow library wasn't compiled to use SSE4.1 instructions, but these are available on your machine and could speed up CPU computations.
2018-07-05 13:50:22.378485: W tensorflow/core/platform/cpu_feature_guard.cc:45] The TensorFlow library wasn't compiled to use SSE4.2 instructions, but these are available on your machine and could speed up CPU computations.
2018-07-05 13:50:22.378490: W tensorflow/core/platform/cpu_feature_guard.cc:45] The TensorFlow library wasn't compiled to use AVX instructions, but these are available on your machine and could speed up CPU computations.
2018-07-05 13:50:22.378494: W tensorflow/core/platform/cpu_feature_guard.cc:45] The TensorFlow library wasn't compiled to use AVX2 instructions, but these are available on your machine and could speed up CPU computations.
2018-07-05 13:50:22.378498: W tensorflow/core/platform/cpu_feature_guard.cc:45] The TensorFlow library wasn't compiled to use AVX512F instructions, but these are available on your machine and could speed up CPU computations.
2018-07-05 13:50:22.378502: W tensorflow/core/platform/cpu_feature_guard.cc:45] The TensorFlow library wasn't compiled to use FMA instructions, but these are available on your machine and could speed up CPU computations.
2018-07-05 13:50:22.553645: I tensorflow/core/common_runtime/gpu/gpu_device.cc:955] Found device 0 with properties:
name: GeForce GTX 1080 Ti
major: 6 minor: 1 memoryClockRate (GHz) 1.6325
pciBusID 0000:17:00.0
Total memory: 10.92GiB
Free memory: 10.76GiB
2018-07-05 13:50:22.553695: I tensorflow/core/common_runtime/gpu/gpu_device.cc:976] DMA: 0
2018-07-05 13:50:22.553701: I tensorflow/core/common_runtime/gpu/gpu_device.cc:986] 0: Y
2018-07-05 13:50:22.553710: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1045] Creating TensorFlow device (/gpu:0) -> (device: 0, name: GeForce GTX 1080 Ti, pci bus id: 0000:17:00.0)
Starting new training run at commit: None
Generated 8 batches of size 2 in 0.000 sec
Generated 32 batches of size 32 in 3.644 sec
Step 1 [5.854 sec/step, loss=1.02402, avg_loss=1.02402]
Step 2 [4.149 sec/step, loss=0.97023, avg_loss=0.99713]
Step 3 [3.071 sec/step, loss=1.03737, avg_loss=1.01054]
Step 4 [2.503 sec/step, loss=1.03371, avg_loss=1.01633]
Step 5 [2.503 sec/step, loss=0.99038, avg_loss=1.01114]
Step 6 [2.196 sec/step, loss=1.00019, avg_loss=1.00932]
4. 음성 합성 진행하기
python3 synthesizer.py --load_path logs/son_2018-07-05_17-23-45 --text "이거 실화냐?"✗ python3 synthesizer.py --load_path logs/son_2018-07-05_17-23-45 --text "이거 실화냐?"
[*] Make directories : samples
[*] Found lastest checkpoint: logs/son_2018-07-05_17-23-45/model.ckpt-65000
Constructing model: tacotron
UPDATE cleaners: english_cleaners -> korean_cleaners
========================================
model_type: single
========================================
Initialized Tacotron model. Dimensions:
embedding: 256
speaker embedding: None
prenet out: 128
encoder out: 256
attention out: 256
concat attn & out: 512
decoder cell out: 256
decoder out (5 frames): 400
decoder out (1 frame): 80
postnet out: 256
linear out: 1025
Loading checkpoint: logs/son_2018-07-05_17-23-45/model.ckpt-65000
2018-07-06 10:07:15.002215: W tensorflow/core/platform/cpu_feature_guard.cc:45] The TensorFlow library wasn't compiled to use SSE4.2 instructions, but these are available on your machine and could speed up CPU computations.
2018-07-06 10:07:15.002238: W tensorflow/core/platform/cpu_feature_guard.cc:45] The TensorFlow library wasn't compiled to use AVX instructions, but these are available on your machine and could speed up CPU computations.
2018-07-06 10:07:15.002245: W tensorflow/core/platform/cpu_feature_guard.cc:45] The TensorFlow library wasn't compiled to use AVX2 instructions, but these are available on your machine and could speed up CPU computations.
2018-07-06 10:07:15.002250: W tensorflow/core/platform/cpu_feature_guard.cc:45] The TensorFlow library wasn't compiled to use FMA instructions, but these are available on your machine and could speed up CPU computations.
plot_graph_and_save_audio: 0%| | 0/1 [00:00<?, ?it/s] [*] Plot saved: samples/2018-07-06_10-07-29.manual.png
[*] Audio saved: samples/2018-07-06_10-07-29.manual.wav
plot_graph_and_save_audio: 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 1/1 [00:13<00:00, 13.68s/it]

"이거 실화냐?"
"이것은 딥 보이스를 활용한 목소리입니다. 반갑습니다"