Tensorflow Object Detection 예제 수행하기
Tensorflow를 활용한 Object Detection을 수행하는 예제를 동작시켜보았습니다. 기존에 Tensorflow가 설치되었다는 가정하에서 진행하겠습니다. 저는 Window 환경에서 수행했습니다. Anaconda를 활용하면 필요한 패키지들이 다 설치되어있는 경우가 많기때문에, 상대적으로 편리하게 수행할 수 있습니다.
필요한 소스코드 가져오기
$ git clone https://github.com/tensorflow/models.git
위의 명령어를 입력하여 Tensorflow Object Detection 예제를 설치합니다.
jupyter notebook 실행하기
설치를 하고 나서는 jupyter notebook을 실행해야 합니다. 아래의 명령어를 입력하여 jupyter notebook을 실행합니다. (Anaconda를 사용하면 쉽지만, 설치가 되어 있지 않은 경우 설치를 진행한 후 아래의 명령어를 수행해야합니다.)
$ jupyter notebook
models/research/objection_detection/ 디렉토리에 들어가서 object_detection_tutorial.ipynb를 실행합니다. 아래의 이미지와 같은 모습을 볼 수 있습니다.
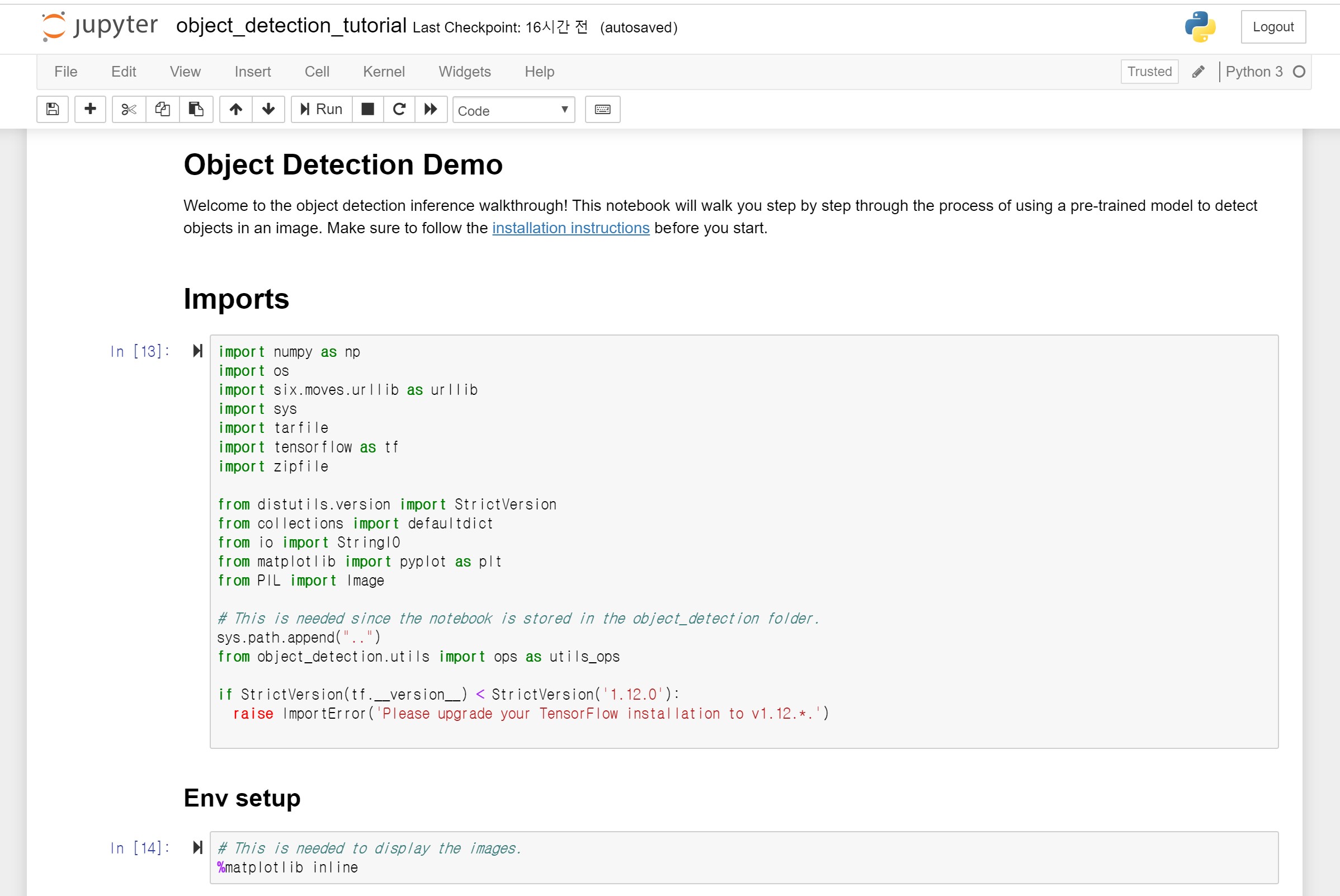 Jupyter Notebook에서 볼 수 있는 데모
Jupyter Notebook에서 볼 수 있는 데모
tests_images 폴더에 이미지 넣기
models/research/objection_detection/test_images 폴더에는 Object Detection 예제가 들어있습니다. 기본 이미지는 image1.jpg, image2.jpg 가 들어있습니다. 추가적으로 Object Detection을 수행하려면 image3.jpg, image4.jpg, imageN.jpg과 같은 형태로 이미지를 넣어주면 Object Detection이 수행됩니다.
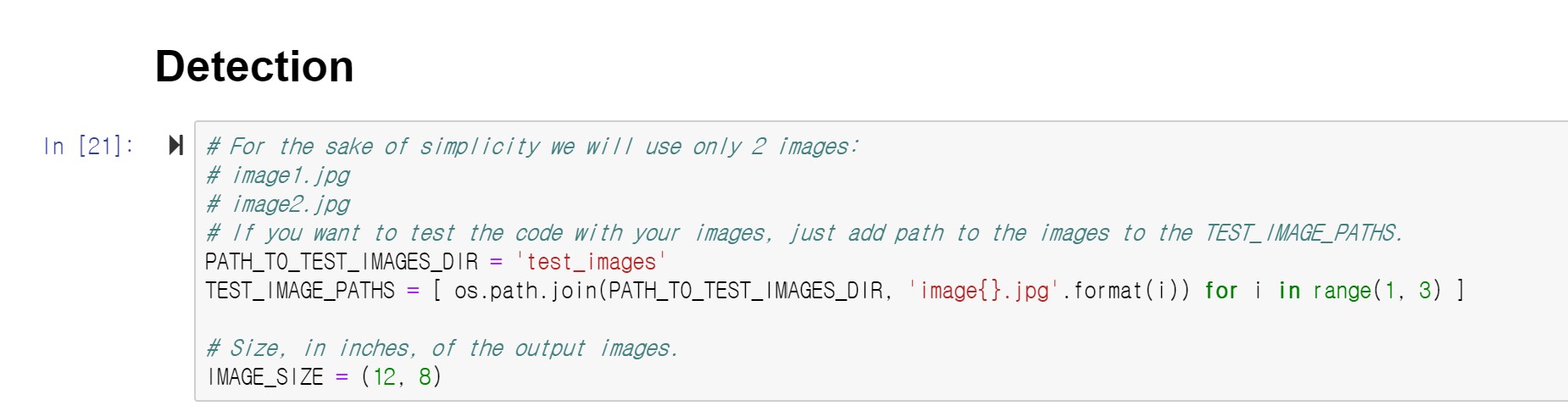 이미지를 추가하고 나면 총 개수만큼 위의 range를 변경시켜야한다
이미지를 추가하고 나면 총 개수만큼 위의 range를 변경시켜야한다
이미지를 추가하고 나면 range의 끝 번호를 총 개수 +1 로 변경시켜야 합니다. 예를 들어, 이미지가 10개라면, range(1,3) -> range(1,11) 로 바꾸어야 합니다.
 2개의 기본 이미지
2개의 기본 이미지
기본 이미지는 위와 같이 강아지와 해변에 있는 이미지입니다. 기본 이미지만으로 예제를 진행해보겠습니다.
코드가 돌아가는 원리
모든 소스코드를 다 보기는 너무 방대하고 간략하게 중요한 부분만 살펴보려고합니다.
Import. 초반부에서는 필요한 라이브러리를 임포트합니다.Model Preparation. 모델을 준비해야 합니다. 기본 모델은 SSD with Mobilenet입니다. detection model zoo에 들어가보면, 해당 모델의 설명과 각 모델의 속도와 정확성을 표로 정리해놓았습니다. 원하는 모델을 선택하여 학습을 수행하면 됩니다. 기본 모델은 SSD with Mobilenet 중에서도 ssd_mobilenet_v1_coco_2017_11_17를 사용했습니다. COCO Data Set1 기반의 모델입니다.Detection. 위에서 불러온 모델을 기반으로 Detection을 수행합니다.
코드 수행하기
차례대로 코드를 수행하면 마지막에 아래와 같은 결과를 얻을 수 있습니다.
 Object Detction 결과 강아지를 높은 확률로 정확하게 감지함
Object Detction 결과 강아지를 높은 확률로 정확하게 감지함
 Object Detction 다양한 사물들을 꽤 정확한 확률로 감지함
Object Detction 다양한 사물들을 꽤 정확한 확률로 감지함
상당히 정확한 결과를 얻은 것을 확인해 볼 수 있습니다.
출처
- https://medium.com/@WuStangDan/step-by-step-tensorflow-object-detection-api-tutorial-part-1-selecting-a-model-a02b6aabe39e