1. MobileNet이 왜 필요할까요?
사물인터넷이나 5G같은 저전력 통신망, 딥러닝이 발달하면서 모든 곳에서 딥러닝을 활용하려고 많은 시도가 이루어지고 있습니다. 이러한 환경에 맞춰 MobileNet이 등장하게 되었는데요. 고성능 환경과 아닌 환경을 비교해보면서 등장 배경을 살펴보겠습니다.
1.1. 고성능의 환경
데이터 센터 환경에서는 고성능의 CPU가 매우 많이 있기 때문에 연산 처리 성능이 매우 고성능이고, 고성능의 그래픽 카드 다수를 가지고 있을 수 있으며, 메모리도 대용량을 사용할 수 있습니다. 또, 전력 공급이 지속적으로 이루어지기 때문에, 전원을 아끼기 위해 성능을 낮추는 것 보다는 더 높은 퍼포먼스에 초점을 두는 경우가 많습니다.
 Google Alphago Tpu Computer
Google Alphago Tpu Computer
구글의 Alphago가 동작되는 컴퓨터 환경을 생각하면 쉽습니다. 판후이와의 대결에서의 알파고는 1202개의 CPU와 176개의 GPU를 사용했고, 2016년 3월의 이세돌 九단과의 대결에서는 GPU대신 48개의 TPU를 사용했다고 합니다. 이 정도의 막대한 컴퓨팅파워를 가진 환경이라면 어떤 모델을 넣더라도 문제가 안 될 것 같습니다.
1.2. 고성능이 아닌 환경
이런 고성능의 디바이스가 아니라 자동차, 드론, 스마트폰과 같은 환경에서는 CPU를 하나 정도 가지고 있는 경우도 많고, GPU가 없을 수도 있으며, 메모리도 부족합니다. 또, 배터리를 사용하는 경우가 많기 때문에, 성능을 높히는 것은 전력 소모가 늘어나기 때문에 어렵습니다. 따라서, 높은 퍼포먼스는 뒷전이고 돌리는 것 자체가 힘들 수 있습니다.
위와 같은 환경에서 CNN을 구동하려면 어떻게 해야 할까요? MobileNet은 컴퓨터 성능이 제한되거나 배터리 퍼포먼스가 중요한 곳에서 사용될 목적으로 설계된 CNN 구조입니다.
개인적으로 처음 MobileNet이라고 했을 때 CPU Clock이 몇 백Hz인 환경을 생각해봤는데, 그런 환경까지의 저수준은 아닌 것 같습니다.
1.3. 클라우드 컴퓨팅 vs 엣지 컴퓨팅
위의 환경에서 함께 알아두면 좋은 개념을 적어보았습니다.
1.3.1. 클라우드 컴퓨팅
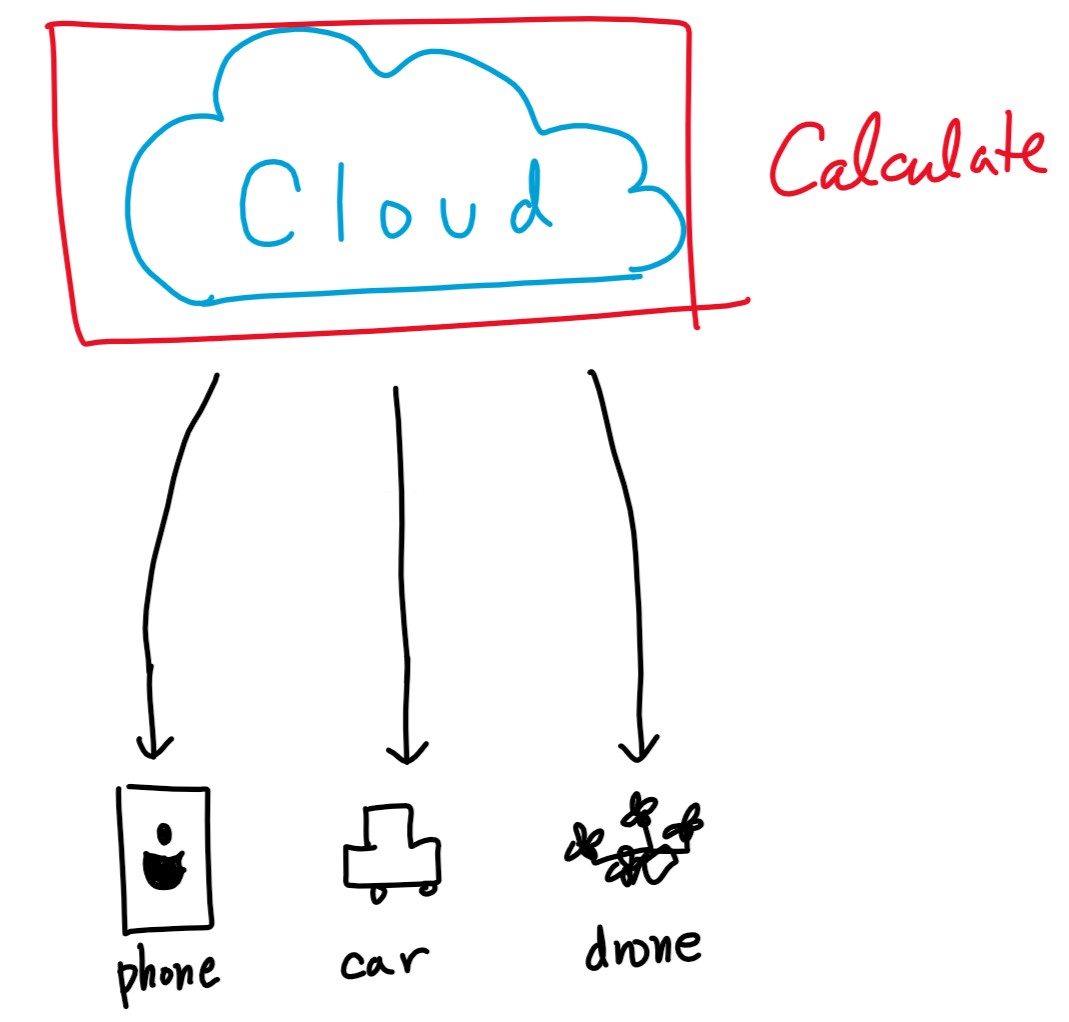 Cloud Computing
Cloud Computing
클라우드 컴퓨팅은 위의 그림과 같이 여러 디바이스들에서 나온 정보들을 클라우드에서 전부 처리하는 환경입니다.
1.3.2. 엣지 컴퓨팅
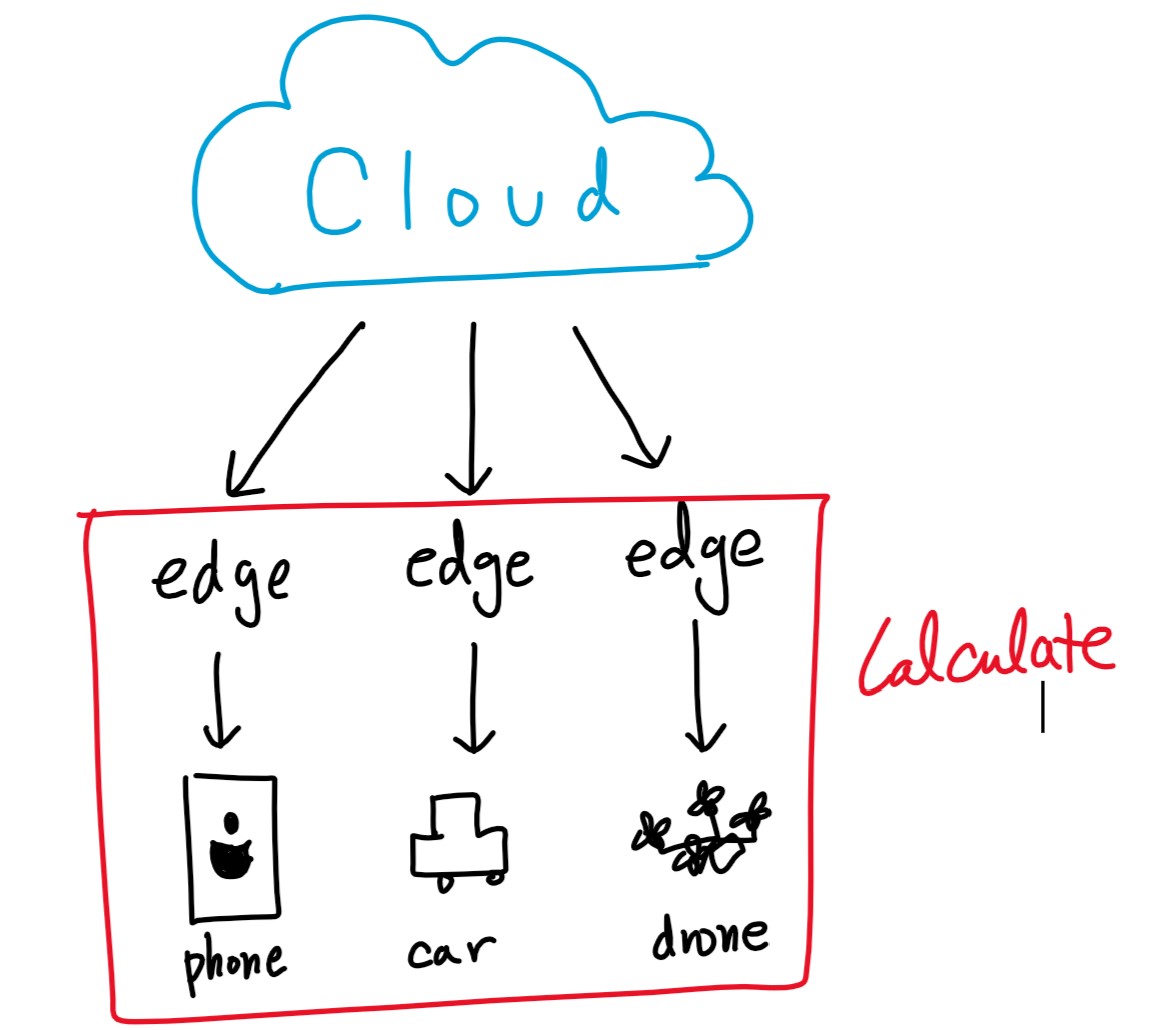 Edge Computing
Edge Computing
엣지 컴퓨팅은 클라우드에서 모든 연산을 처리 하는 것이 아니라, 모바일 디바이스들이 직접 연산을 하거나 edge들에서 데이터 연산을 하여 cloud 에 데이터를 뿌려주는 것입니다. 우리가 MobileNet을 사용하려는 환경들이라고 볼 수 있죠.
1.4. 고성능이 아닌 환경에서의 CNN 예시
네트워크들은 향상된 성능만큼이나 비대해져 갔으며 alexnet 시절 8층의 네트워크는 Resnet에 이르러서는 152층에 이르게 되었다고 합니다. 이렇게 비대한 크기의 네트워크보다는 빠른 성능이 필요한 곳에서 MobileNet을 사용합니다.
갤럭시 S7을 이용한 모바일 넷 예시 블로그에서 실제 구동하고 있는 것을 확인할 수 있습니다. 굉장히 잘 동작하고 있네요.
2. MobileNets Architecture
2.1. 작은 신경망을 만들기 위한 기술들
 techniques for small dnn
techniques for small dnn
빨간 글씨가 MobileNets에서 사용됨.
- Remove Fully-Connected Layers
- CNN에서 파라미터의 90% 정도가 Fully-Connected Layers에 들어가기 때문에, 얘를 줄여야됨!
- Kernel Reduction
- 3×3 → 1×1 을 통하여 연산량을 줄인다.
- Channel Reduction
- 채널 수를 줄인다.
- Evenly Spaced Downsampling
- 초반에 Downsampling을 많이 : accuracy가 떨어지지만, 파라미터가 적어짐.
- 후반에 Downsampling을 많이 : accuracy가 좋지만, 파라미터 많아짐.
- 적당히 사용하는 것이 중요.
- Depthwse Separable Convolutions
- Shuffle Operations
- Distillation & Compression
2.2. 기존의 CNN
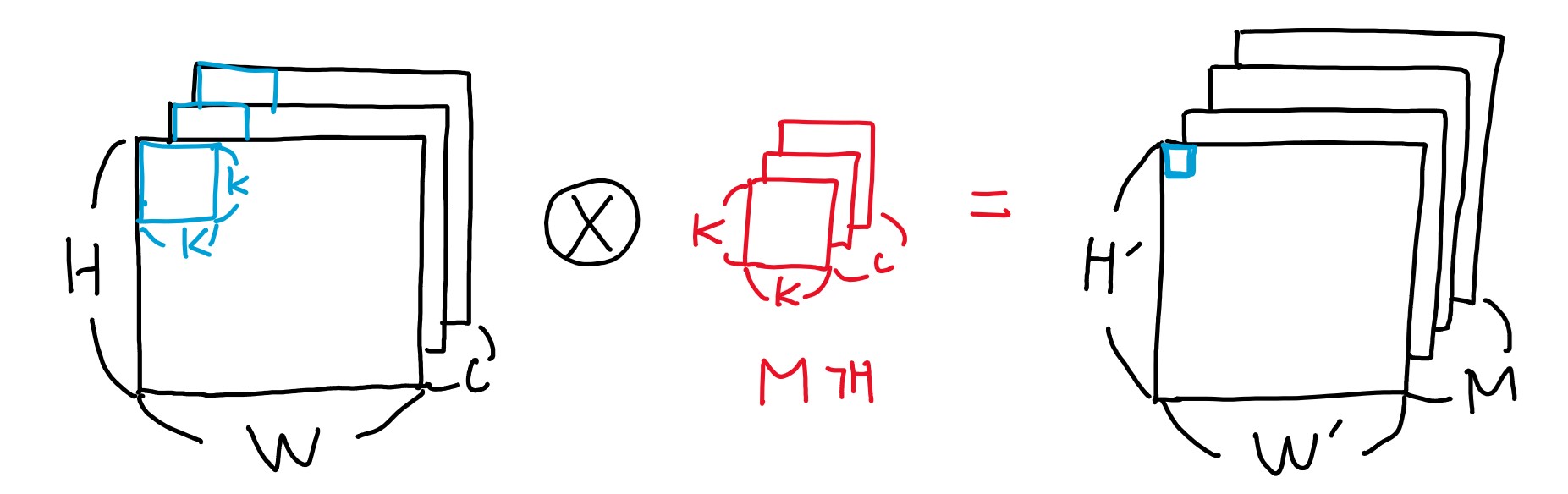 기존 CNN의 구조
기존 CNN의 구조
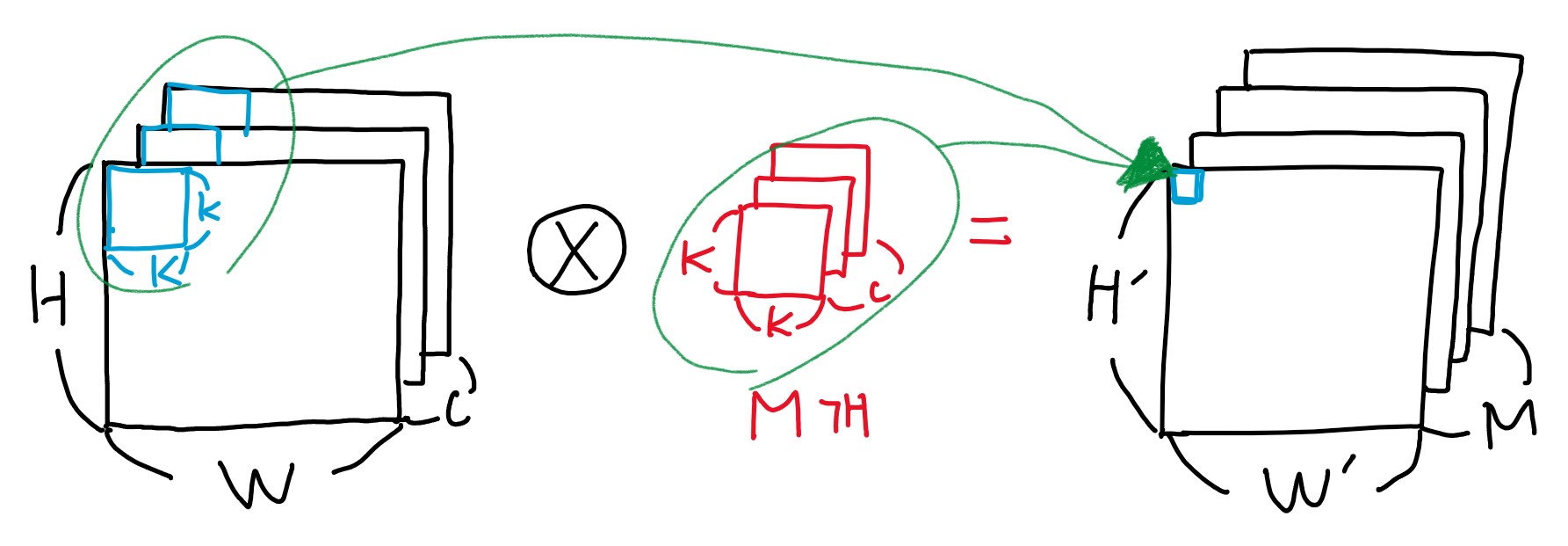 기존 CNN의 구조2
기존 CNN의 구조2
기존의 CNN 구조는 위와 같이 연산됩니다. H×W 크기의 C 채널 이미지에 K×K×C 크기의 M개를 곱하여 H’×W’ 크기의 M 채널 이미지를 생성합니다. (채널은 RGB 같은 이미지 색의 표현 층이라고 생각하면 됩니다.)
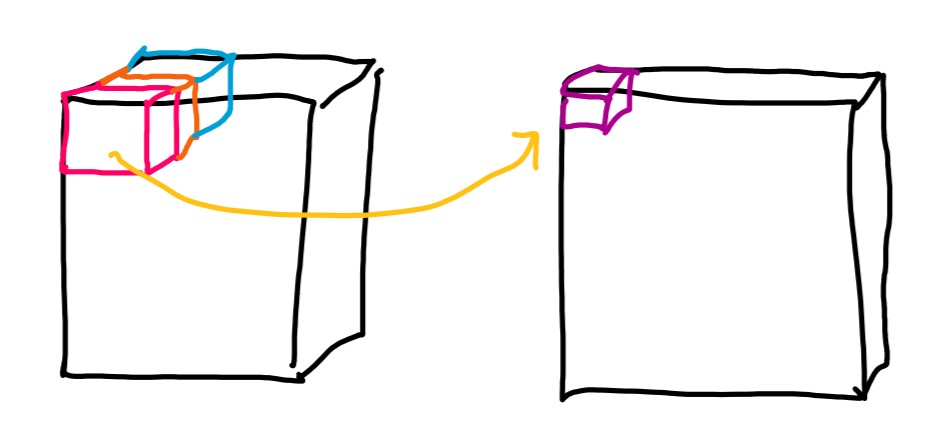 기존 CNN의 구조3
기존 CNN의 구조3
한 채널의 변화를 살펴보면 왼쪽의 임의의 크기와 채널의 공간이 점 하나로 축소되는 것이죠.
2.3. Depthwise & Pointwise Covolution
기존 CNN의 구조와 달리 한 방향으로만 크기를 줄이는 전략이라고 보시면 됩니다.
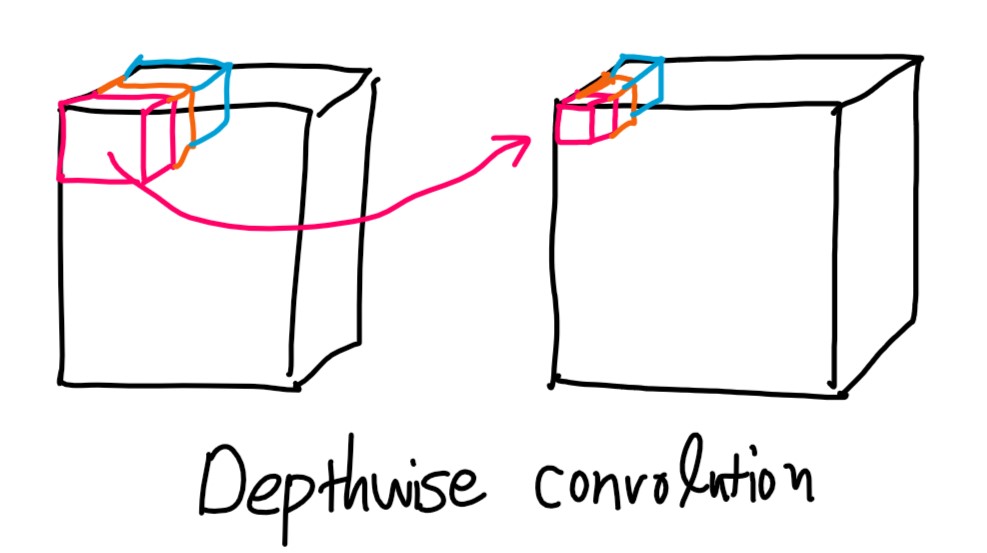 depthwise convolution
depthwise convolution
depthwise convolution은 채널 숫자는 줄어들지 않고 한 채널에서의 크기만 줄어듭니다.
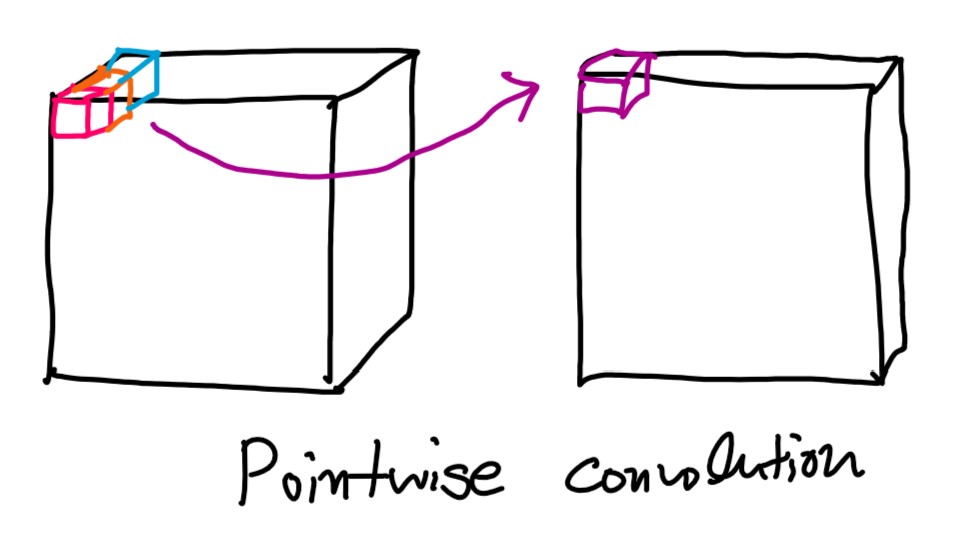 pointwise convolution
pointwise convolution
pointwise convolution은 채널 숫자가 하나로 줄어듭니다.
2.4. 계산량 비교
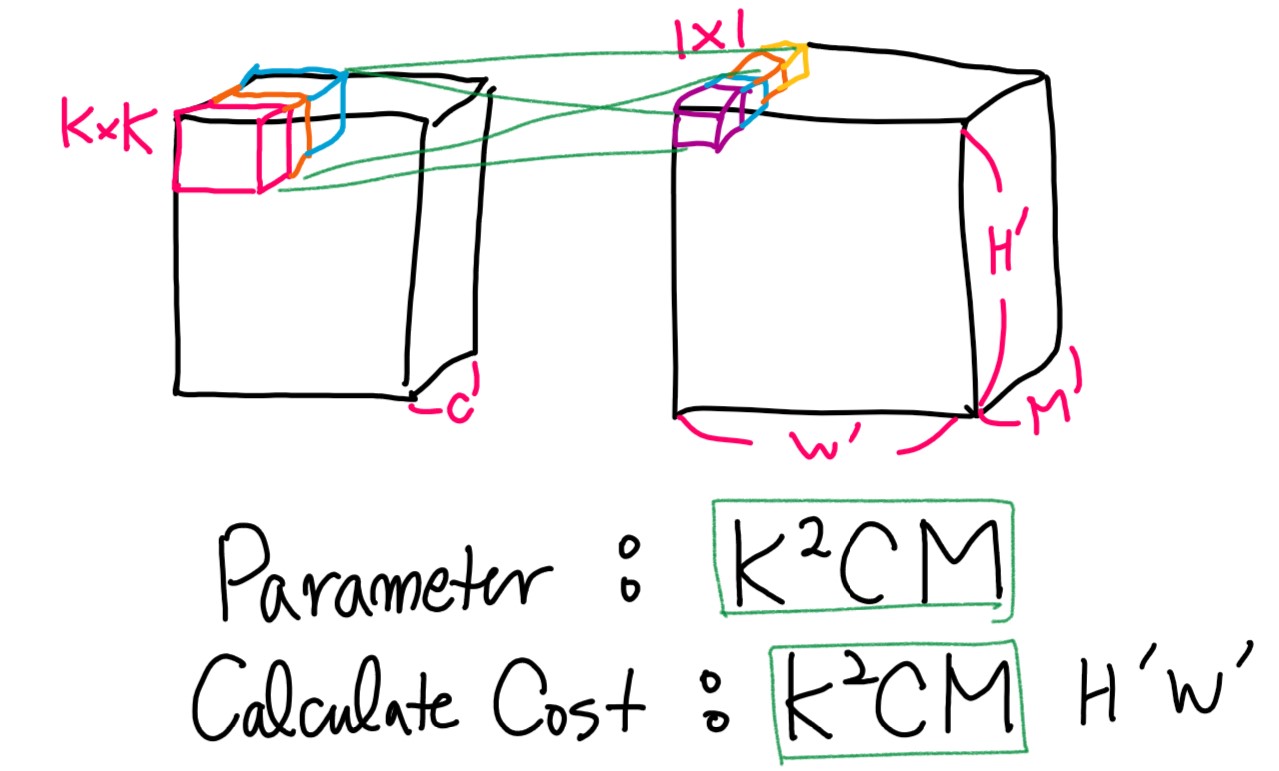 Basic Cnn parameter & calculation
Basic Cnn parameter & calculation
기존 CNN 같은 경우 위와 같은 파라미터 크기와 계산량을 가집니다.
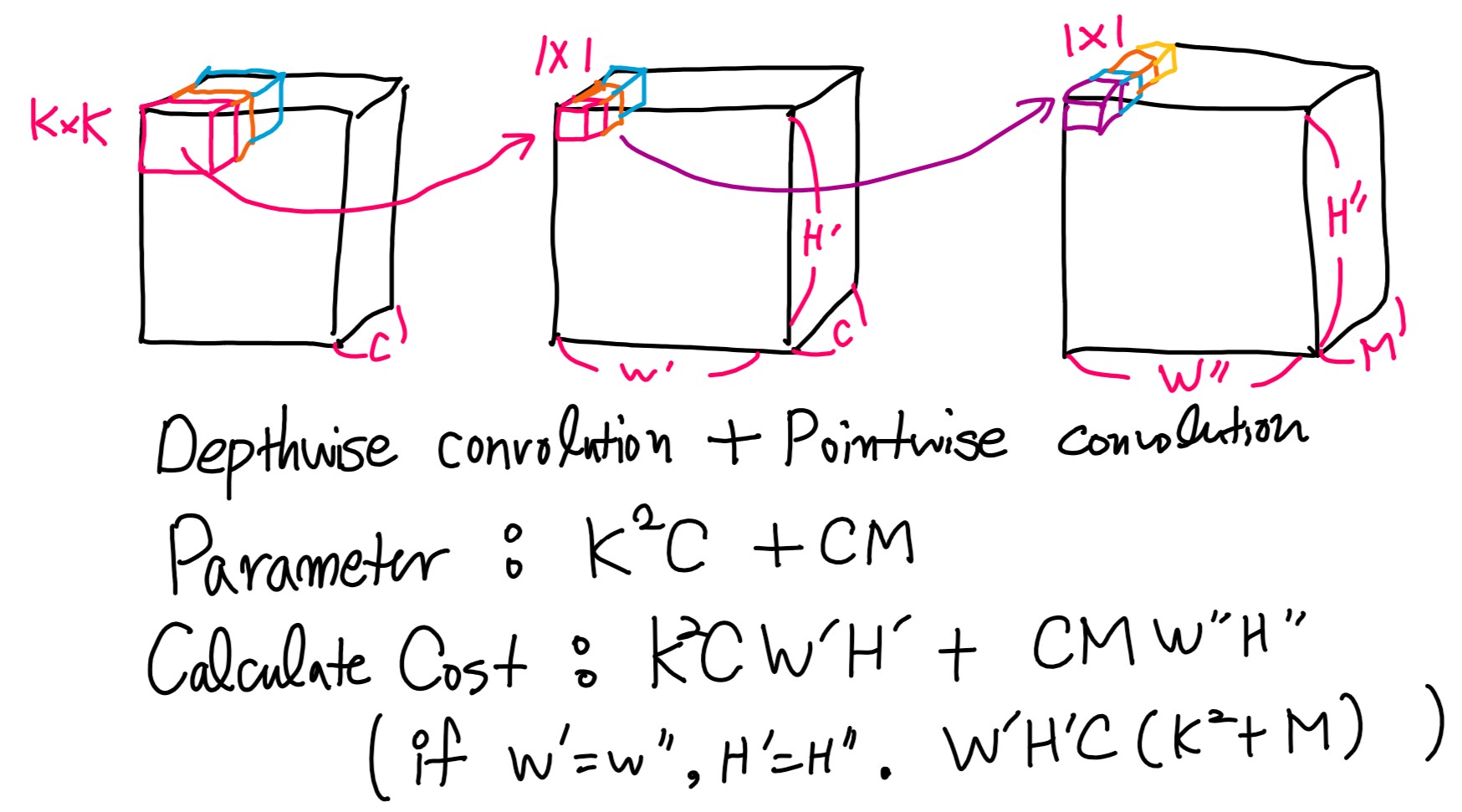 Depthwse Separable Convolutions parameter & calculation
Depthwse Separable Convolutions parameter & calculation
Depthwise convolution + Pointwise convolution 혼합인 Separable Convolutions에서는 위와 같은 계산량을 보여줍니다.
$ W = W’ = W’’ , H = H’ = H’’ $ 이라고 가정하고, 연산량 차이를 구해보면 아래와 같습니다.
\[\left( \frac{(K^{2}+M)WHC }{(K^{2}M)WHC} \right) = \left( \frac{K^{2}+M}{K^{2}M} \right) = \left( \frac{1}{M} + \frac{1}{K^{2}} \right)\]위와 같은 식에서 K가 3인 경우에, 대략 8~9배 정도의 효율을 얻을 수 있다고 합니다.
2.5. Depthwse Separable Convolutions 효율 비교
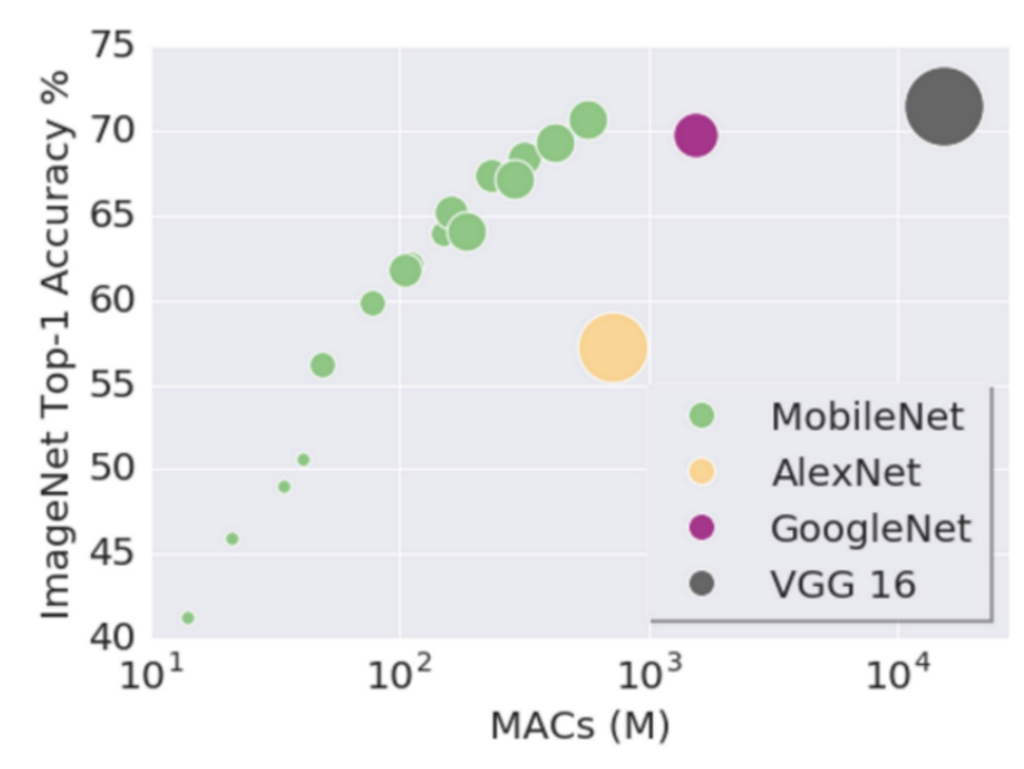 imagenet accuracy compare
imagenet accuracy compare
연산량 대비
출처
- https://hugrypiggykim.com/2018/06/08/mobilenets-efficient-convolutional-neural-networks-for-mobile-vision-applications/
- https://deepmi.me/deeplearning/74/
- https://www.youtube.com/watch?v=7UoOFKcyIvM&list=WL&index=23&t=748s
- https://namu.wiki/w/%EC%95%8C%ED%8C%8C%EA%B3%A0
- https://research.google.com/seedbank/seed/mobile_net