deep voice를 이용한 TTS(Text-To-Speech) 구현하기 _ 김앵커 한마디 학습
http://melonicedlatte.com/2018/07/02/215933.html
위의 링크에서 원래 github 데이터를 통하여 손석희 아나운서의 데이터를 학습하는 것을 확인할 수 있습니다.
일단 손석희 아나운서의 데이터는 이상 없이 학습 되었고, 원하는 text에 맞춰서 음성을 생성할 수 있다는 것을 확인했습니다.
아래의 모든 과정은 https://github.com/melonicedlatte/multi-speaker-tacotron-tensorflow 링크에서 확인하실 수 있습니다.
0. 데이터 선정하기
다음으로는 '김앵커 한마디' 를 기반으로 학습을 진행하였습니다.
'김앵커 한마디'는 jtbc 에서 김종혁 기자가 1~2분 내외로 짧게 이야기 하는 채널입니다.
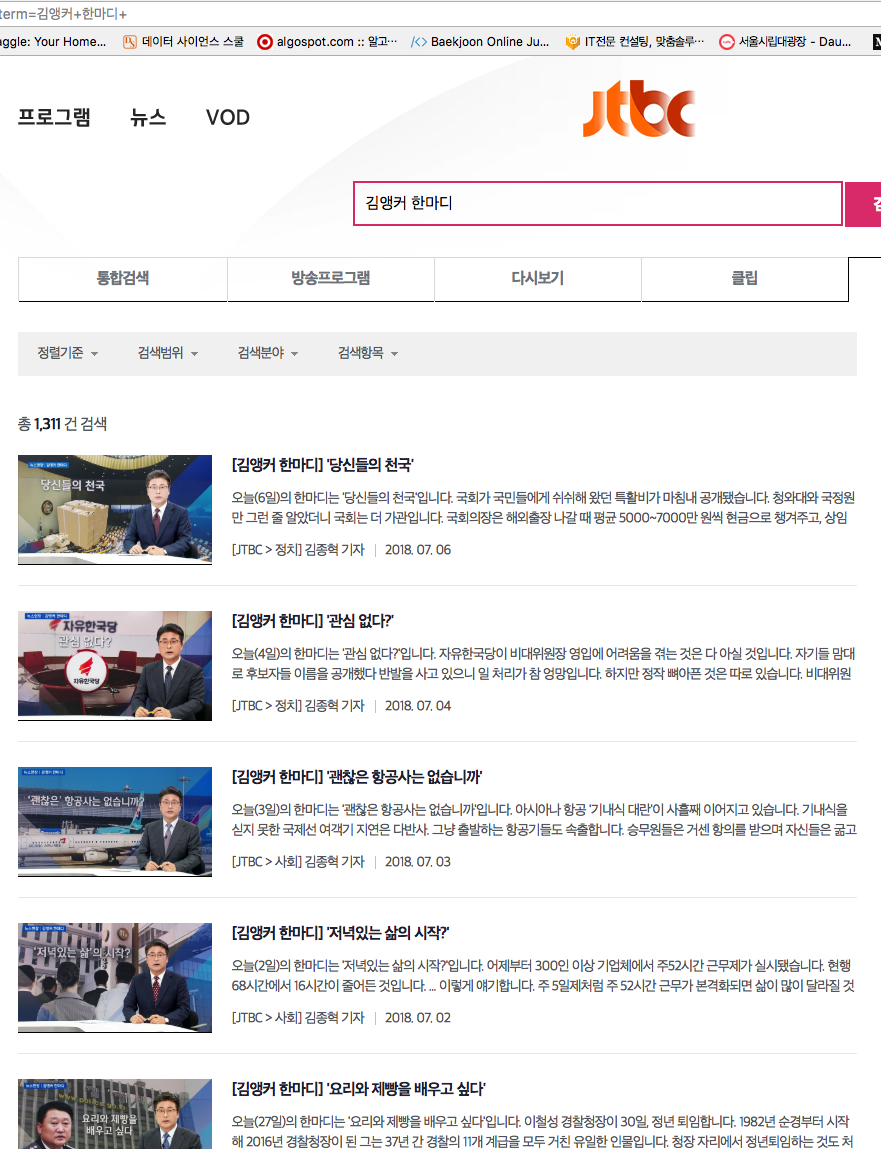
jtbc 홈페이지에서 검색하면 위와 같이 많은 프로그램이 있는 것을 확인할 수 있습니다.
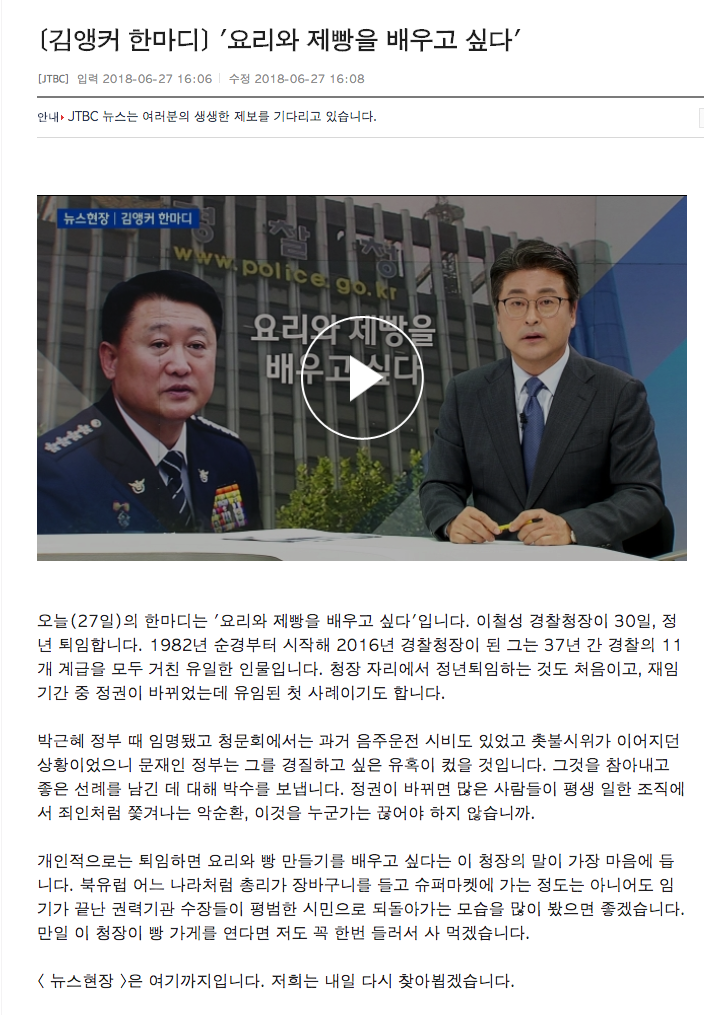
이 데이터를 선정한 이유 중 하나는 '대사 스크립트'가 있다는 것입니다.
1. 데이터 수집하기
1-0. 배경 음악 문제 해결하기 과정 시행 착오 모음
실제 다운로드 진행은 1-1 부터 진행됩니다.
원래 소스와 별개로 jupyter 환경에서 python 을 이용하여 크롤링을 하려고 시도를 했는데, 영상 다운로드와 관련하여 잘 진행되지 않았습니다.
영상 다운로드 소스코드만 가져와서 동일한 확장자를 가진 동영상을 음성으로 바꾸려는 도중에, 잘 작동하지 않았습니다.
수 많은 삽질 끝에 김앵커 한마디를 가져오기 위해서, 결국 원래 있는 소스코드를 활용하고 약간의 소스 코드 변경을 통하여 데이터를 수집하였습니다.
python3 -m datasets.kim_anchor.download
sudo python3 -m audio.silence --audio_pattern "./datasets/kim_anchor/audio/*.wav" --method=pydub하지만 현재 상태에서의 소리를 위의 코드를 말이 없는 '침묵' 구간을 기준으로 잘라내면 문제가 생깁니다.
하나의 예시로 한 파일이 단 2개의 파일로 잘리는 경우가 있습니다.
그 이유는 위의 영상을 들어보시면 나오는 '배경음악' 입니다.
'배경음악' 이 들어가기 때문에 공백을 만들지 못하고, 따라서 제대로 나눌 수 없게 되는 것입니다.
그래서 저는 '전처리' 과정이 필요하다고 생각하고, 여러 프로그램 소스나 방법들을 찾아보았는데 ffmpeg 를 이용하는 것이 가장 나아 보였습니다.
ffmpeg에 -af "highpass=f=800, lowpass=f=400" 옵션을 추가해주었습니다.
대역필터를 설정하는 명령어인데, 정확한 내용은 ffmpeg 공식 사이트가 잠시 정지되어 들어가지 못하였으나, 테스트 해본 결과 배경음이 덜 들리고 목소리가 깔끔하게 들리는 정도라고 생각하여 위의 값으로 정했습니다.
ffmpeg -i ./NB11139438.wav -af "highpass=f=750, lowpass=f=400" ./test.wav
명령어는 terminal 에서 위와 같이 사용하는 것이 예시입니다.
( son download.py 에도 동영상에서 음원만 추출하기 위하여 사용된 ffmpeg 명령어가 숨어있습니다.
거기에 -af 명령어를 추가하여 음원을 추가로 처리 해줍니다.
올린 소스코드에는 전부 반영 되어 있습니다. )
command = '{} -y -loglevel panic -i {} -ab 160k -ac 2 -ar 44100 -vn -af "highpass=f=800, lowpass=f=400" {}'.\아래의 파일은 변환한 파일 중 하나입니다.
배경음이 많이 줄어든 것을 확인할 수 있었습니다.
! '그런데 위의 파일로 아래의 과정들을 모두 수행했더니 소리가 너무 작아서 학습이 늦어지는?' 것 같은
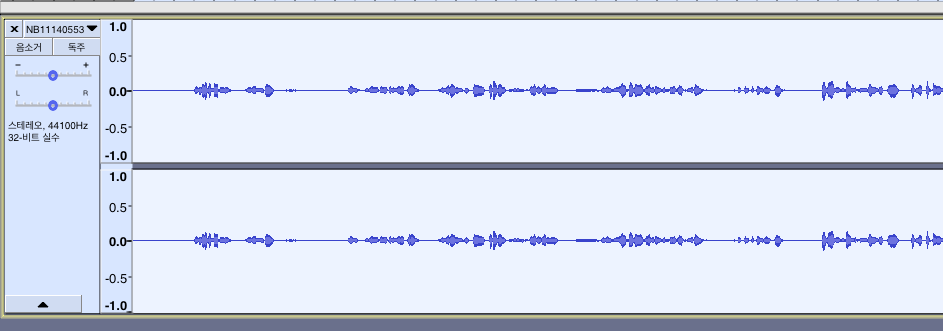
손석희 데이터의 원래 음파는 아래와 같습니다. 진폭 자체가 크게 다른 것을 확인할 수 있습니다.
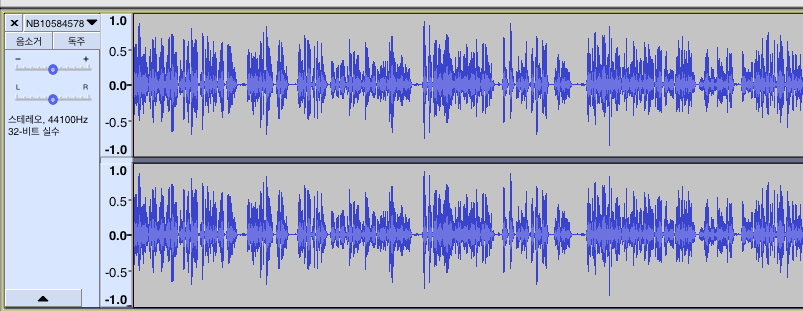
아래와 같은 명령어로 소리를 증폭시켰습니다.
ffmpeg -i ./NB11140553_sub.wav -filter:a "volume=15" ./NB11140553_amp.wav
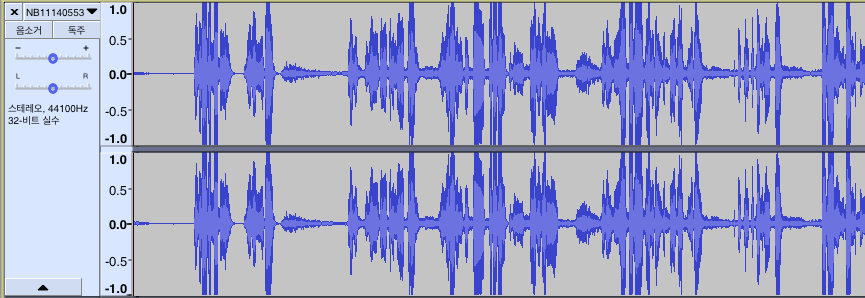
그러면 진폭이 크게 상승하는 것을 확인할 수 있습니다. ( download.py를 수정했기 때문에 해당 파일로 다운 받았으면 이미 증폭이 되어 있습니다 )
진폭이 상승한 음원 파일을 아래와 같습니다.
소리가 크게 상승했습니다.
하지만 생각보다 노이즈가 많이 줄지 않았습니다. 또, 소리가 생각보다 울리고 좋지 않은 현상을 가졌습니다.
그래서 찾아보다가 sox 라는 것을 찾게 되었습니다.
아래의 명령어를 통하여 sox 를 설치하였습니다.
brew install sox
아래와 같이 sox 를 적용하면 소리가 변하는 것을 확인할 수 있습니다.
ffmpeg 를 쓰는 것 보다 효과적인 것 같아서 sox를 쓰기로 했습니다.
>> 원래 파일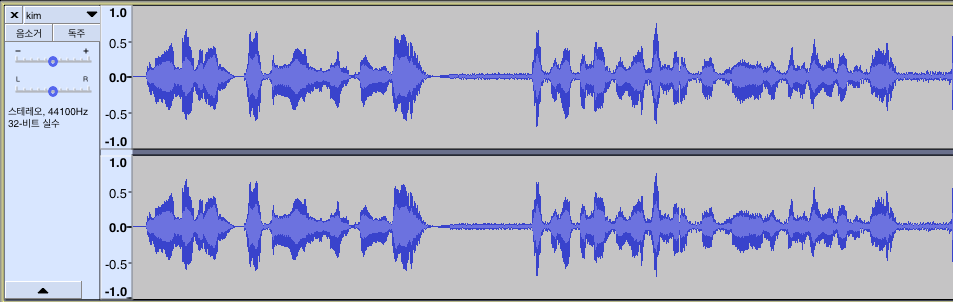
>> sox 를 적용한 파일 
중간 중간에 들어간 소리가 말끔하게 없어진 것을 확인할 수 있습니다.
In:100% 00:01:46.56 [00:00:00.00] Out:4.70M [!=====|=====!] Hd:0.0 Clip:7
sox WARN noisered: noisered clipped 4 samples; decrease volume?
sox WARN dither: dither clipped 3 samples; decrease volume?
Done.
In:23.9% 00:00:19.32 [00:01:01.56] Out:0 [ | ] Clip:0 NB11332808 | 50/606 [01:04<12:01, 1.30s/it]
[<article_title><![CDATA[[김앵커 한마디] '정말로 그랬습니까']]></article_title>]
In:100% 00:01:39.03 [00:00:00.00] Out:4.37M [!=====|=====!] Hd:0.0 Clip:436
sox WARN noisered: noisered clipped 229 samples; decrease volume?
sox WARN dither: dither clipped 207 samples; decrease volume?
Done.
In:45.9% 00:00:37.15 [00:00:43.72] Out:0 [ | ] Clip:0 NB11271453 | 51/606 [01:05<11:55, 1.29s/it]
[<article_title><![CDATA[[김앵커 한마디] '검사가 된 이유']]></article_title>]
Input File : '/Users/imjaegon/programming/인공지능/deep_voice/datasets/kim_anchor/audio/../audio_raw/NB11332808_raw.wav'
Channels : 2
Sample Rate : 44100
Precision : 16-bit
Duration : 00:01:33.81 = 4136960 samples = 7035.65 CDDA sectors
File Size : 16.5M
Bit Rate : 1.41M
Sample Encoding: 16-bit Signed Integer PCM
In:64.3% 00:00:52.01 [00:00:28.86] Out:0 [ | ] Clip:0
Input File : '/Users/imjaegon/programming/인공지능/deep_voice/datasets/kim_anchor/audio/../audio_raw/NB11271453_raw.wav'
Channels : 2
Sample Rate : 44100
Precision : 16-bit
Duration : 00:01:15.56 = 3332096 samples = 5666.83 CDDA sectors
File Size : 13.3M
Bit Rate : 1.41M
Sample Encoding: 16-bit Signed Integer PCM
audio_raw 폴더를 추가하고, 해당 내용을 download.py 에 적용했습니다.
실제 수행은 아래의 과정을 따라하시면 됩니다.
1-1. 데이터 셋 다운로드
다른 소스코드에서 크롤링을 통하여 아래와 같이 kim_anchor 폴더 안에 news_ids.json 파일을 미리 생성해 놓았습니다.

그리고 아래의 명령어를 다시 실행시켜서 전처리를 진행했습니다.
python3 -m datasets.kim_anchor.download
1-2. audio 파일을 '말이 없는 구간(침묵)'에서 자르기
python3 -m audio.silence --audio_pattern "./datasets/kim_anchor/audio/*.wav" --method=pydub
위처럼 잘 끊어진 것을 확인할 수 있습니다.
하지만 '문장 단위'라기 보다는 '단어 뭉치' 같은 느낌으로 더 많이 쪼개지는 것 같았습니다.
일단은 학습 결과가 어떻게 될 지 몰라 계속 진행했습니다.
1-3. 일정 시간보다 긴 파일이나 짧은 파일을 삭제합니다.
저는 용량이 300KB~1MB 인 오디오 파일들만 남겨놓고 나머지는 제거했습니다.
그 이외의 데이터들은, 상대적으로 유의미한 결과를 가져오기 어렵다고 생각해서 입니다.
python3 -m audio.audio_range --load_path ./datasets/kim_anchor/audio
./datasets/kim_anchor/audio
0%| | 0/12110 [00:00<?, ?it/s]NB11480883.0021.wav
NB11480883.0021.wav / size is == 425696
/home/gon/programming/deep_voice
NB11527274.0005.wav
NB11527274.0005.wav / size is == 1112776
/home/gon/programming/deep_voice
./datasets/kim_anchor/audio/NB11527274.0005.wav is removed!!
NB11461428.0016.wav
NB11461428.0016.wav / size is == 337676
/home/gon/programming/deep_voice
NB11650120.0025.wav
NB11650120.0025.wav / size is == 493436
/home/gon/programming/deep_voice
NB11239274.0015.wav
NB11239274.0015.wav / size is == 179972
/home/gon/programming/deep_voice
./datasets/kim_anchor/audio/NB11239274.0015.wav is removed!!
1-4. Google Speech Recognition API 를 사용하여, 오디오에 대한 문장을 출력해줍니다.
sudo python3 -m recognition.google --audio_pattern "./datasets/kim_anchor/audio/*.*.wav"[*] Removed: ./datasets/kim_anchor/audio/NB11253530.0025.tmp.wav
text_recognition_batch: 11%|██████████████ | 3103/27027 [57:12<7:21:00, 1.11s/it]./datasets/kim_anchor/audio/NB11253530.0023.wav 사장님들 직원가
[*] Removed: ./datasets/kim_anchor/audio/NB11253530.0023.tmp.wav
./datasets/kim_anchor/audio/NB11253530.0024.wav 언론에 수시로 보도되는 민물가
[*] Removed: ./datasets/kim_anchor/audio/NB11253530.0024.tmp.wav
text_recognition_batch: 11%|██████████████ | 3105/27027 [57:12<7:20:44, 1.11s/it]./datasets/kim_anchor/audio/NB11253530.0026.wav 아래서도 이러는 분들이 더 높은 자리에 가면 어찌 된
터미널을 확인해보면 위와 같이 오디오 파일을 글씨로 인식하고 있습니다.
많이 자르는 듯한 느낌이 있지만 일단 진행시켜봅니다.
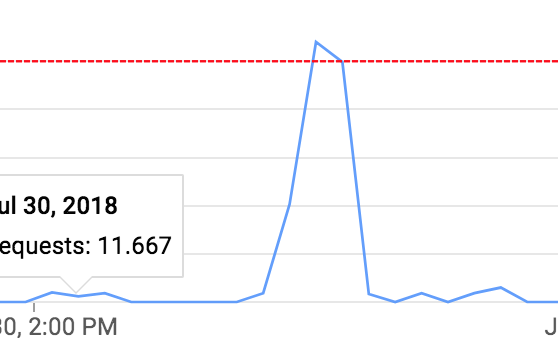
기존 소스코드에 google speech api 속도 문제가 있어서, sleep 함수를 코드로 추가했습니다.
그냥 동작시키면 500 회 호출을 초과해서 에러가 납니다.
sleep 함수를 써주면 매끄럽게 진행됩니다.
Exception: OS error: RetryError(Exception occurred in retry method that was not classified as transient, caused by <_Rendezvous of RPC that terminated with:
status = StatusCode.RESOURCE_EXHAUSTED
details = "Insufficient tokens for quota 'Default_Group' and limit 'CLIENT_PROJECT-100s' of service 'speech.googleapis.com' for consumer 'project_number:~~~~~~'."
debug_error_string = "{"created":"@~~~~~~","description":"Error received from peer","file":"src/core/lib/surface/call.cc","file_line":1083,"grpc_message":"Insufficient tokens for quota 'Default_Group' and limit 'CLIENT_PROJECT-100s' of service 'speech.googleapis.com' for consumer 'project_number:~~~~~~~'.","grpc_status":8}">)
1-5. 인식된 텍스트와 진짜 텍스트를 비교하기 위하여, 음성 파일과 텍스트 파일을 쌍으로 연결한 내용을 alignment.json 에 저장합니다.
python3 -m recognition.alignment --recognition_path "./datasets/kim_anchor/recognition.json" --score_threshold=0.5align_text_batch: 100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 18331/18331 [00:07<00:00, 2303.83it/s]
[*] # found: 1.00000% (18331/18331)
[*] # exact match: 0.10561% (1936/18331)
100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 18331/18331 [00:14<00:00, 1280.37it/s]
[*] Total Duration : 4:46:37 (file #: 18331)
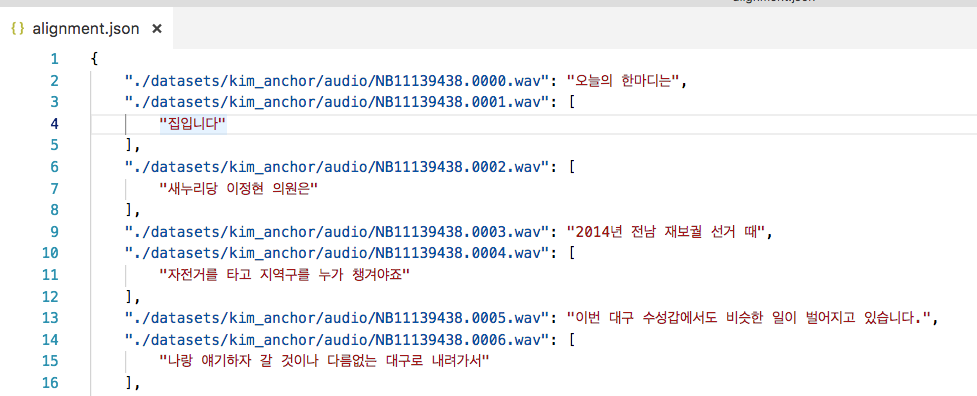
위와 같은 json 파일이 생성됩니다.
1.6 학습에 사용될 numpy 파일을 생성해줍니다.
python3 -m datasets.generate_data ./datasets/kim_anchor/alignment.json
python3 -m datasets.generate_data ./datasets/kim_anchor/alignment.json$ python3 -m datasets.generate_data ./datasets/kim_anchor/alignment.json
========================================
[!] Sampling rate: 22050
========================================
[!] Audio not found: ['./datasets/kim_anchor/audio/NB11306246.0005.wav', './datasets/kim_anchor/./datasets/kim_anchor/audio/NB11306246.0005.wav']
[!] Audio not found: ['./datasets/kim_anchor/audio/NB11402440.0010.wav', './datasets/kim_anchor/./datasets/kim_anchor/audio/NB11402440.0010.wav']
[!] Audio not found: ['./datasets/kim_anchor/audio/NB11462941.0000.wav', './datasets/kim_anchor/./datasets/kim_anchor/audio/NB11462941.0000.wav']
[!] Audio not found: ['./datasets/kim_anchor/audio/NB11607695.0049.wav', './datasets/kim_anchor/./datasets/kim_anchor/audio/NB11607695.0049.wav']
[!] Skip recognition level: 0 (use all)
5%|█████ | 1005/18327 [00:27<07:53, 36.61it/s]
2. 학습하기
명령 창에 아래와 같은 명령어를 입력해서 multi 학습을 진행해줍니다.
python3 train.py --data_path=datasets/son,datasets/kim_anchor/기존에 손석희 모델 위에 학습하려고 했는데, 해당 작업은 안 되는 것 같습니다.
명령어를 입력하면 아래와 같은 글자들이 출력되면서 학습이 시작됩니다.
Hyperparameters:
adam_beta1: 0.9
adam_beta2: 0.999
attention_size: 128
attention_state_size: 256
attention_type: bah_mon
batch_size: 32
cleaners: korean_cleaners
dec_layer_num: 2
dec_prenet_sizes: [256, 128]
dec_rnn_size: 256
decay_learning_rate_mode: 0
dropout_prob: 0.5
embedding_size: 256
enc_bank_channel_size: 128
enc_bank_size: 16
enc_highway_depth: 4
enc_maxpool_width: 2
enc_prenet_sizes: [256, 128]
enc_proj_sizes: [128, 128]
enc_proj_width: 3
enc_rnn_size: 128
frame_length_ms: 50
frame_shift_ms: 12.5
griffin_lim_iters: 60
ignore_recognition_level: 0
initial_data_greedy: True
initial_learning_rate: 0.001
initial_phase_step: 8000
main_data: ['']
main_data_greedy_factor: 0
max_iters: 200
min_iters: 30
min_level_db: -100
min_tokens: 50
model_type: deepvoice
num_freq: 1025
num_mels: 80
post_bank_channel_size: 128
post_bank_size: 8
post_highway_depth: 4
post_maxpool_width: 2
post_proj_sizes: [256, 80]
post_proj_width: 3
post_rnn_size: 128
power: 1.5
preemphasis: 0.97
prioritize_loss: False
recognition_loss_coeff: 0.2
reduction_factor: 5
ref_level_db: 20
sample_rate: 22050
skip_inadequate: False
speaker_embedding_size: 16
use_fixed_test_inputs: False
filter_by_min_max_frame_batch: 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 37926/37926 [00:33<00:00, 1118.96it/s]
[datasets/son/data] Loaded metadata for 11753 examples (13.82 hours)
[datasets/son/data] Max length: 991
[datasets/son/data] Min length: 150
filter_by_min_max_frame_batch: 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 18327/18327 [00:12<00:00, 1492.70it/s]
[datasets/kim_anchor/data] Loaded metadata for 459 examples (0.40 hours)
[datasets/kim_anchor/data] Max length: 480
[datasets/kim_anchor/data] Min length: 150
========================================
{'datasets/kim_anchor/data': 0.5, 'datasets/son/data': 0.5}
========================================
filter_by_min_max_frame_batch: 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 37926/37926 [00:33<00:00, 1146.34it/s]
[datasets/son/data] Loaded metadata for 11753 examples (13.82 hours)
[datasets/son/data] Max length: 991
[datasets/son/data] Min length: 150
filter_by_min_max_frame_batch: 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 18327/18327 [00:11<00:00, 1633.44it/s]
[datasets/kim_anchor/data] Loaded metadata for 459 examples (0.40 hours)
[datasets/kim_anchor/data] Max length: 480
[datasets/kim_anchor/data] Min length: 150
========================================
{'datasets/kim_anchor/data': 0.5, 'datasets/son/data': 0.5}
========================================
========================================
model_type: deepvoice
========================================
Initialized Tacotron model. Dimensions:
embedding: 256
speaker embedding: None
prenet out: 128
encoder out: 256
attention out: 256
concat attn & out: 512
decoder cell out: 256
decoder out (5 frames): 400
decoder out (1 frame): 80
postnet out: 256
linear out: 1025
========================================
model_type: deepvoice
========================================
Initialized Tacotron model. Dimensions:
embedding: 256
speaker embedding: None
prenet out: 128
encoder out: 256
attention out: 256
concat attn & out: 512
decoder cell out: 256
decoder out (5 frames): 400
decoder out (1 frame): 80
postnet out: 256
linear out: 1025
2018-07-10 11:17:31.062812: W tensorflow/core/platform/cpu_feature_guard.cc:45] The TensorFlow library wasn't compiled to use SSE4.1 instructions, but these are available on your machine and could speed up CPU computations.
2018-07-10 11:17:31.062840: W tensorflow/core/platform/cpu_feature_guard.cc:45] The TensorFlow library wasn't compiled to use SSE4.2 instructions, but these are available on your machine and could speed up CPU computations.
2018-07-10 11:17:31.062846: W tensorflow/core/platform/cpu_feature_guard.cc:45] The TensorFlow library wasn't compiled to use AVX instructions, but these are available on your machine and could speed up CPU computations.
2018-07-10 11:17:31.062851: W tensorflow/core/platform/cpu_feature_guard.cc:45] The TensorFlow library wasn't compiled to use AVX2 instructions, but these are available on your machine and could speed up CPU computations.
2018-07-10 11:17:31.062857: W tensorflow/core/platform/cpu_feature_guard.cc:45] The TensorFlow library wasn't compiled to use AVX512F instructions, but these are available on your machine and could speed up CPU computations.
2018-07-10 11:17:31.062862: W tensorflow/core/platform/cpu_feature_guard.cc:45] The TensorFlow library wasn't compiled to use FMA instructions, but these are available on your machine and could speed up CPU computations.
2018-07-10 11:17:31.196088: I tensorflow/core/common_runtime/gpu/gpu_device.cc:955] Found device 0 with properties:
name: GeForce GTX 1080 Ti
major: 6 minor: 1 memoryClockRate (GHz) 1.6325
pciBusID 0000:17:00.0
Total memory: 10.92GiB
Free memory: 10.76GiB
2018-07-10 11:17:31.196119: I tensorflow/core/common_runtime/gpu/gpu_device.cc:976] DMA: 0
2018-07-10 11:17:31.196125: I tensorflow/core/common_runtime/gpu/gpu_device.cc:986] 0: Y
2018-07-10 11:17:31.196133: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1045] Creating TensorFlow device (/gpu:0) -> (device: 0, name: GeForce GTX 1080 Ti, pci bus id: 0000:17:00.0)
Starting new training run at commit: None
Generated 8 batches of size 4 in 0.000 sec
Generated 32 batches of size 32 in 3.478 sec
Step 1 [5.809 sec/step, loss=0.96202, avg_loss=0.96202]
Step 2 [3.455 sec/step, loss=0.93932, avg_loss=0.95067]
Step 3 [3.208 sec/step, loss=0.85928, avg_loss=0.92020]
Step 4 [3.073 sec/step, loss=0.80743, avg_loss=0.89201]
Step 5 [2.840 sec/step, loss=0.61149, avg_loss=0.83591]
Step 6 [2.563 sec/step, loss=0.64586, avg_loss=0.80423]
학습에는 다소 시간이 소요됩니다.
3. 데이터 문제 발생 -> 다시 전처리
하지만 학습을 하다보니 학습이 잘 되지 않았습니다.
단독 데이터를 120,000 step, 학습된 손석희 모델에 추가로 학습을 시켜도,
새로 다시 2개의 데이터의 학습을 함께 진행해도 학습이 매우 부족했습니다.

데이터 전처리에 이상이 있다고 생각하고 다시 데이터를 전처리 했습니다.
용량이 적거나 큰 파일들은 그냥 모두 제거했습니다.(300KB 이하, 1MB 이상)
300KB이하의 데이터만 4000개가 넘었습니다.
그리고 음질이 깨지는 데이터를 어느 정도 골라내었습니다.
또, 텍스트 용량이 너무 작은 (90byte 미만) 파일들도 제거했습니다.
(위 파일에는 모두 적용 되었습니다. )
하지만 위와 같은 데이터에도 문제가 있었고, 내부 소스코드를 다소 수정하여 김앵커 데이터 1시간을 얻어 내고 손석희 데이터를 기반으로 학습시켰습니다.
4. 다시 학습 후 결과
python3 train.py --data_path=datasets/kim_anchor/ --initialize_path=logs/PATH_TO_CHECKPOINT
위의 명령어를 통하여 손석희 데이터를 기반으로 학습을 진행시켰습니다.
학습은 데이터가 적어서 오히려 학습을 많이 진행할 수록 좋은 데이터가 나오지는 않았습니다.
만족할만한 결과는 아니지만 괜찮은 결과는 얻은 것 같습니다.

영웅은 죽지 않아요
하지만 사회적 존경에 수반되는 책임을 이행하지 못하면 그만큼 가중처벌해야 하는 거 아닙니까?
간장 공장 공장장은 강 공장장이고 된장 공장 공장장은 공 공장장이다
썩 결과가 좋지는 않지만 그래도 몇 문장은 흉내는 낼 수 있네요
관련 문의 같은 내용은 댓글이나 메일로 주시면 바로 답변 드리겠습니다~